The following is a description of the main components of the IBM Batch architecture; it is important to understand the capabilities of each in order to replicate them on an open container-based architecture.
- JCL
- JES
- Application programs (COBOL, PL/I, etc.)
- Data (files and databases).
JCL
We can think of a JCL as a distant ancestor of a DAG (Directed Acrylic Graph), it is a set of sentences, inherited from punch card technology, that define the process and the sequence of steps to be executed.
In the JCL we find the basic characteristics of the process or job (name, type, priority, resources allocated, etc.), the sequence of programmes to be executed, the sources of input information and what to do with the output data of the process.
The main statements found in a JCL are the following
- A JOB card, where the name of the process and its characteristics are defined.
- One or more EXEC cards with each program to be executed.
- One or more DD cards defining the files (data sets) used by the previous programs.
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=PROGRAM1
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JES
The JES is the z/OS component (subsystem) responsible for batch processing. It performs two main tasks:
- Scheduling the batch processes
- Assigning the process to a class or initiator (jobs can be assigned to specific queues)
- Defining the priority of the process
- Allocating/limiting the resources assigned to the process (memory, time, etc.)
- Control the execution sequence (STEPs) of the process
- Execute programs
- Validate the JCL statements
- Loading programs (COBOL, PL/I) into memory for subsequent execution
- Assigning the input/output files to the symbolic names defined in the COBOL PL/I application programs
- Logging
Application programs
Programs, usually coded in COBOL, that implement the functionality of the process.
The executable program resulting from the compilation of the source code is stored as a member of a partitioned library (PDS). A specific card in the JCL (JOBLIB / STEPLIB) identifies the libraries from which the programs are to be loaded.
The JES calls the main program of the process (defined in the EXEC card of the JCL), which in turn can call various subroutines statically or dynamically.
Data
Data is accessed mainly through the use of files (datasets) and relational databases (DB2).
The input and output files are defined in the programs by means of a symbolic name.
SELECT LOAN ASSIGN TO "INPUT1"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
The assignment of symbolic names to read/write files is done in the JCL, via the DD card.
//*
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
The files are generally of one of the following types
- Sequential, the records must be accessed sequentially, i.e. to read the 1000th record, the previous 999 records must be read first.
- VSAM. There are different types of VSAM files, and it is possible to access the records directly using a key (KSDS) or a record number (RRDS).
In the case of access to a database (DB2), the information necessary for the connection (security, database name, etc.) is passed as parameters in the JCL.
Mainframe Batch Migration to Open Architecture
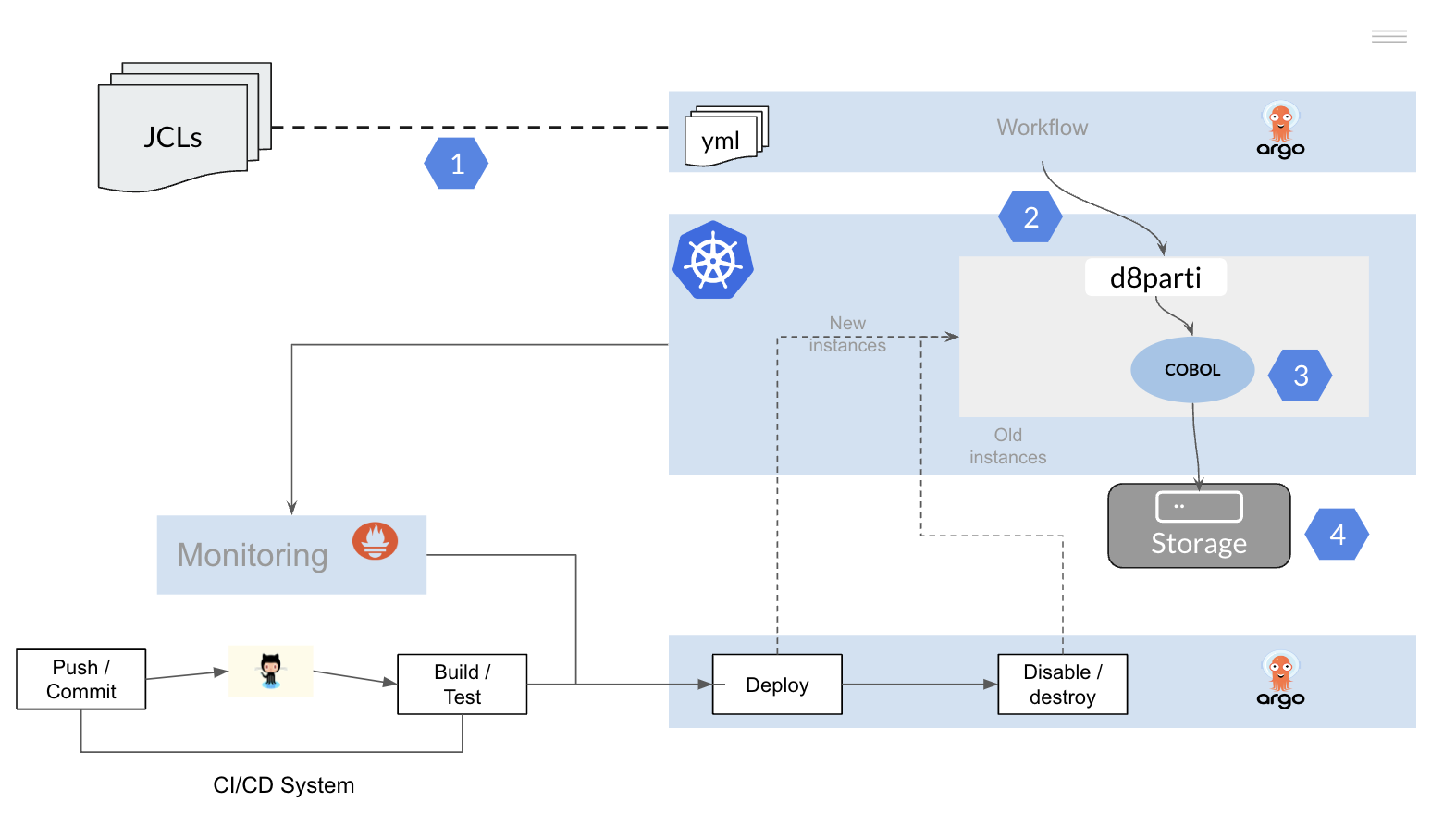
To migrate batch processes built on mainframe technology, we will replicate the functionality described above on a Kubernetes cluster.
It is therefore necessary to:
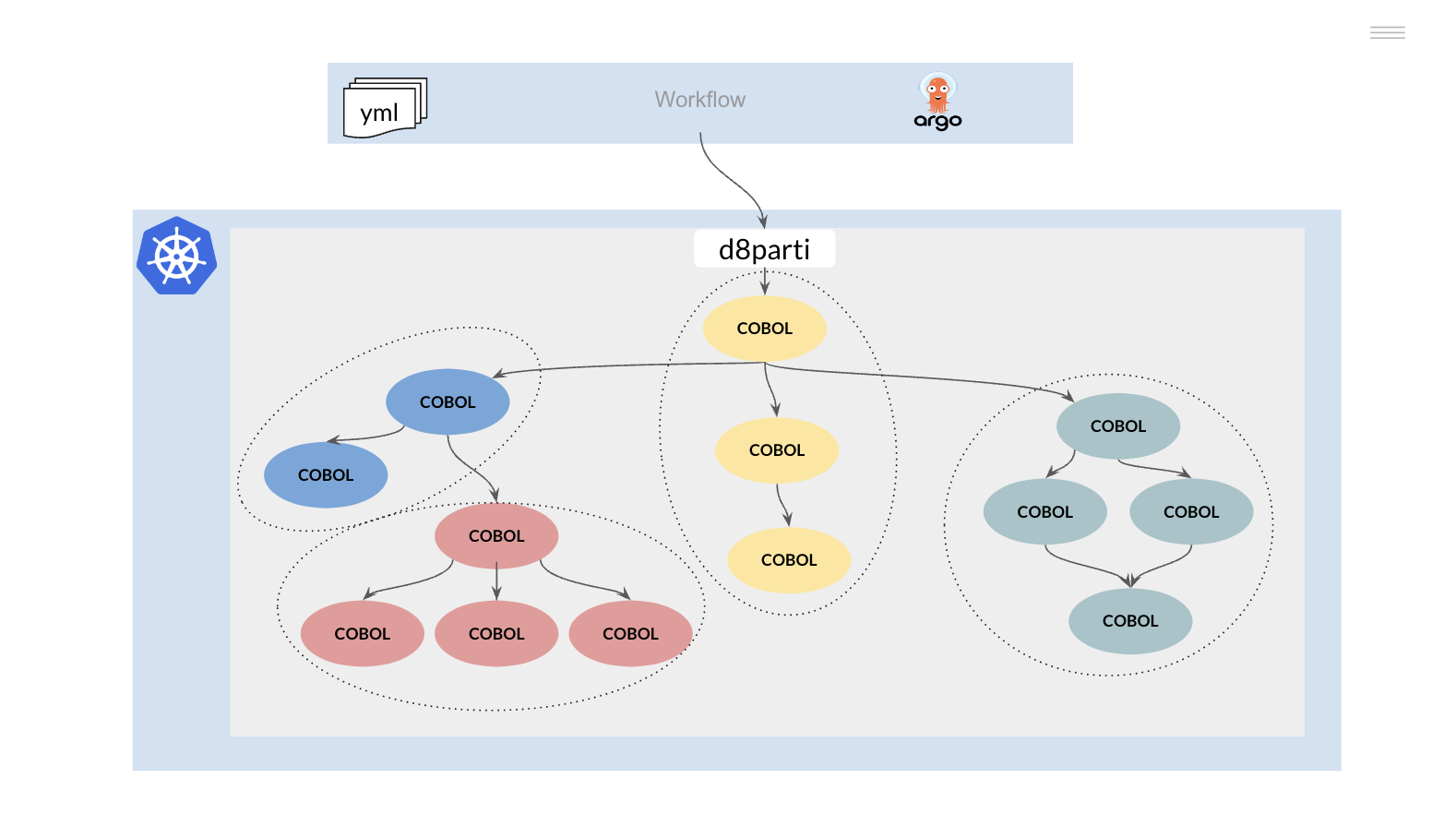
- Convert the JCLs (JOBs) to a tool or framework that allows the execution of workflows on a Kubernetes platform.
- Replicate the functionality of the JES to allow the scheduling and execution of COBOL PL/I programs on the Kubernetes cluster.
- Recompile the application programs.
- Provide access to data (files and databases).