Learn about key mainframe concepts and how this technology can be translated into a modern cloud-native platform, compile a COBOL program and deploy it as an API, find tutorials and reference material.
This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Overview
- 2: Getting Started
- 3: Examples
- 3.1: Hello World
- 3.2: COBOL gRPC server
- 3.3: Playing with PostgreSQL
- 3.4: Calling COBOL containers
- 3.5: COBOL & Kafka
- 3.6: JCL to DAG
- 3.7: COBOL to Go
- 3.8: Python
- 4: Concepts
- 4.1: Strangler Fig Pattern
- 4.2: Microservice model
- 4.3: Online Architecture
- 4.4: Batch architecture
- 4.4.1: Converting JCLs
- 4.4.2: Replicate JES functionality
- 4.4.3: Program compilation
- 4.4.4: Data access
- 5: Tutorials
- 5.1: COBOL variables
1 - Overview
Deploy your legacy mainframe code as microservices on a hybrid cloud architecture.
What is driver8?
driver8 is a project that makes it possible to re-use the assets that were developed on an IBM mainframe architecture on a cloud architecture.
There are several alternatives for the migration of mainframe applications to a native cloud architecture:
- Rebuid
- Refactor
- Replace
driver8 makes it possible to combine the above alternatives according to the needs of the project.
Rebuild
Mainframe applications can be redesigned, rewritten (java, python, go, …) and deployed as microservices. By enabling cross-platform coexistence through two basic mechanisms, these new microservices can be deployed incrementally;
- Real-time data access (proxy to DB2 z/OS database).
- Execution of transactions under the CICS / IMS monitors.
Refactor
COBOL programs can be recompiled and exposed as microservices. These microservices can communicate with any other microservice, regardless of the programming language used (COBOL, java, python, go,…) and inherit all the functionalities of the technical platform (authorisation, encryption, monitoring, automation of deployments, etc).
Replace
Finally, the functionality can be replaced by a third-party software. Microservices can easily communicate with the APIs provided by the product.
Why migrate transactions and batch processes to a cloud platform?
Code developed on a mainframe server still implements critical functions in many organisations. In the financial market (retail banking), most accounting processes and product operations are still based on IBM mainframe technology. In many cases, the cost, risk and timeframe of rewriting thousands of programs or replacing such functionality with a third party product is not feasible.
In this case, the code can be reused on an open platform. This allows you to take advantage of a hybrid cloud architecture.
Which applications are best suited for migration?
Any online or batch mainframe application is suitable for migration. However, certain applications are easier to migrate. Use the following list to identify the best candidates for migration;
- Use technical architectures in the CICS/IMS transactional monitors
The purpose of a technical architecture is to isolate the application programs from the complexities of the monitor being used (sending and receiving messages, logging, error handling, etc).
The programs do not execute CICS/IMS statements and can be compiled directly.
- Data stored in DB2
Using product drivers (jdbc, odbc), DB2 provides real-time access to data.
SQL statements can be pre-processed to access a non-Mainframe relational database manager (e.g. PostgreSQL).
- Batch processing using sequential files (QSAM)
Files can be easily transferred and processes can be run in parallel on both platforms to check output results.
What do you need to consider before you start the migration?
Application Inventory
The existence of thousands of components (source code, copies, JCLs, etc.) in the mainframe change management tool does not mean that all of these components are still in use.
Define the scope of the project by creating a detailed inventory of active software components.
Analyse the relationships between the components
By analysing the relationships between components, it is possible to identify application repos that will be deployed together at a later stage.
Lack of knowledge, lack of documentation
Although it is possible to test the migrated functionality by performing a binary check of the process results (messages, files, etc.), the applications must be maintained in the new technical architecture.
A well-trained team is essential to ensure the success of the migration project and the future evolution of the software, except for sunset applications.
VSAM files
This type of file can be replicated on the target platform (Berkley DB). However, it adds a level of complexity that could be avoided by migrating the data and applications to a SQL database.
The fields in the file are converted to columns (SQL database) and depending on the file type:
- KSDS, the key is converted into a unique cluster index
- RRDS, in which a counter is used as the cluster index
- ESDS, in this case the table is sorted using a TIMESTAMP
Other Programming Languages
Although most of the development work on the mainframe platform is carried out using the COBOL programming language, there may be applications that use programs or routines written in any of the following languages:
- PL/I. PL/I programs can be compiled and executed as microservices using the same architecture as COBOL programs. However, there is currently no stable open PL/I compiler. It is therefore necessary to use a licensed product from a third party vendor.
- Assembler. Assembler routines must be converted to C or Go code.
EBCDIC
The mainframe platform uses EBCDIC. Although it is possible to continue using EBCDIC on the Linux platform (intel/arm) in order to minimise changes to the migrated COBOL programs, this option presents serious compatibility and development problems, so we discourage its use.
COBOL programs must be checked for statements that use EBCDIC characters (VARIABLE PIC X(3) VALUE X’F1F2F3’).
3270 applications
In conversational or pseudo-conversational transactions, the execution/navigation flow and the presentation layer are coded in mainframe programs. Although it is possible to build a “3270 controller”, this type of transactions has limited usability due to the protocol they implement (SNA LU2).
In digital channels, where user experience is a critical issue in the design of the solution, they cannot be reused.
Technology not supported
- IMS/DB database manager.
- 4GL tools, Natural/Adabas, IDMS, CA-gen, etc.
If you are interested in any of these technologies, or would like to help develop them, please let us know.
If you want to know more about driver8
- Get started with driver8: Develop your first COBOL API
- Examples: COBOL example programs!
2 - Getting Started
Learn how to expose a COBOL program as a modern REST API
You’ll learn how to expose a COBOL program as a modern REST API. Along the way, you will:
- Install COBOL (if you haven’t already done so).
- Write a simple “hello world” program.
- Compile it as a COBOL subroutine and test it.
- Build a REST API with your code.
Prerequisites
- Some programming experience. The “Hello, world” example is fairly simple, but you will need to compile it statically.
- Understanding of the basic concepts of Go cgo.
- A tool for editing your code. As mentioned above, the code is pretty simple, so any text editor you have will work. Editors such as VSCode (free) have support for a variety of languages through extensions.
- A command terminal. Linux and Mac terminals.
Install GNUCobol
You’ll need a Linux COBOL compiler. A 64-bit compiler is recommended, you can use GNUCobol to compile and run the following examples.
It is possible to use third party COBOL compilers, whether licensed or open source, as long as they allow the COBOL code to be called from within C programmes.
Step1. If you’re using MacOS Install Homebrew
Step2. Install GNUCobol, open a terminal and run the following command (MacOS):
brew install gnu-cobol
For Linux users, please run the corresponding command.
Step3. Check if it is installed correctly using the below command:
cobc -v
Write some code
Get started with Hello, world
- Open a command prompt and cd to your home directory.
cd
- Create a hello directory for your Hello COBOL source code. For example:
mkdir hello
cd hello
-
In your text editor, create a file called hello.cbl in which you will write your code.
-
Copy the following code into your hello.cbl file and save it.
IDENTIFICATION DIVISION.
PROGRAM-ID. hello.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* In COBOL, you declare variables in the WORKING-STORAGE section
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 INPUT-NAME PIC X(10).
01 OUTPUT-PARM.
05 PARM1 PIC X(07).
05 PARM2 PIC X(10).
PROCEDURE DIVISION USING INPUT-NAME, OUTPUT-PARM.
MOVE "Hello," TO PARM1.
IF INPUT-NAME IS EQUAL TO (SPACES OR LOW-VALUES)
MOVE "World" TO PARM2
MOVE 2 TO RETURN-CODE
ELSE
MOVE INPUT-NAME TO PARM2
MOVE 0 TO RETURN-CODE
END-IF.
GOBACK.
The COBOL program hello (COBOL subroutine) receives a &name (INPUT-NAME) and returns “Hello, &name” (OUTPUT-PARM). In case a name is not provided returns “Hello, World”.
- Compile your hello COBOL subroutine
cobc -c -O -fstatic-call hello.cbl
It’ll create a hello.o object in your hello directory
- You need a main program to test your hello subroutine. Create a file launch.cbl and copy the following code:
IDENTIFICATION DIVISION.
PROGRAM-ID. launch.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* Declare program variables
01 INPUT-NAME PIC X(10).
01 OUTPUT-PARM PIC X(17).
PROCEDURE DIVISION.
* code goes here!
DISPLAY "Your name: " WITH NO ADVANCING.
ACCEPT INPUT-NAME.
CALL 'hello' USING INPUT-NAME, OUTPUT-PARM.
DISPLAY OUTPUT-PARM.
DISPLAY "Return Code: " RETURN-CODE.
STOP RUN.
- Compile it and static linking with the subroutine
cobc -c -x launch.cbl
cobc -x launch.o hello.o
./launch
Write a REST API
We’ll use Go to build a web service layer. Your Go API will statically link the hello COBOL subroutine using cgo.
- You need to install Go
You can find instalation packages for MacOS and Linux, here. Follow the instructions to install the latest stable version.
- Verify that you’ve installed Go. Open a command prompt and type:
go version
- Open a terminal and create the following directorys to store your code.
├── greetings
│ └── include
│ └── libs
│ go.mod
│ go.sum
│ main.go
greetings -> Go programs
greetings/include -> .h files
greetings/libs -> hello.o (COBOL routine)
Navigate to your go/src directory and use the following commands
mkdir greetings
mkdir greetings/include
mkdir greetings/libs
- Define a go.mod file to enable dependency tracking for your code.
cd greetings
go mod init example/greetings
go: creating new go.mod: module example/greetings
go: to add module requirements and sums:
go mod tidy
- Create a main.go file using your text editor and copy the following code
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": d})
}
- Let’s execute your first Go API
go mod tidy
go run .
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /hello --> main.getName (3 handlers)
[GIN-debug] GET /hello/:name --> main.getName (3 handlers)
[GIN-debug] [WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.
Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.
[GIN-debug] Listening and serving HTTP on localhost:8080
Your API is running, open a new terminal and use curl to test it.
curl http://localhost:8080/hello
curl http://localhost:8080/hello/Hooper
Link your REST API with the COBOL module
- Ok, now you need to modify your main.go program
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
In the main function initialize the cobol runtime
C.cob_init(C.int(0), nil)
We´re not using arguments, so it’s easy to pass a null pointer.
You need to create a new function to call your COBOL hello routine.
o := callhello(d)
- Copy this code, just before the main function.
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
- Your are using Go cgo, define de C functions and import the “C” package. Copy this code right after the initial package main line.
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnu-cobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
The ‘C’ package will use the comments defined before the ‘C’ import. Do not group import packages to ensure that import “C” is encoded just below the comments.
#cgo CFLAGS: -I${SRCDIR}/include
Define where Go will find the .h files.
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnu-cobol/3.2/lib -lcob
Define the location of your COBOL module (hello.o) and COBOL runtime.
Please check your package manager to find where gnucobol is installed, for example in MacOs with arm architecture the location is /opt/homebrew/Cellar/gnu-cobol/3.2/lib
- This is the complete main.go code
package main
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
-
Copy COBOL hello.o module to your /greetings/libs directory
-
Define hello.h in your /greetings/include directory
cd include
Create a hello.h file and copy the following code
extern int hello(char* inputName, char* outputParm);
Try it out!
-
If the server is still running, stop it.
-
From the command line in the directory containing main.go, run the code.
go run .
- Test it using curl
curl http://localhost:8080/hello
curl http://localhost:8080/hello/Hooper
Write more code
With this quick introduction, you’ve learned how to use Go to expose your COBOL code as a modern REST API. To write some more code, take a look at the Examples chapter.
3 - Examples
Run COBOL code outside the mainframe!
Here is a set of sample programs that will allow you to technically validate the possibilities of migrating your mainframe code to an open architecture.
The code has been simplified to make it understandable to anyone with minimal programming skills.
You can download the code from the following project at GitHub
Want to pilot driver8 with your programs?
Please contact us.3.1 - Hello World
Turn a COBOL program into a REST API.
Breathe new life into your COBOL code. Learn how to build REST APIs using Go cgo.
package main
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
For more information see Getting Started.
3.2 - COBOL gRPC server
Creation of a gRPC server from the COPYBOOK.
Convert a COPYBOOK into a proto-message. Replace the CICS IMS with a modern and efficient RPC-based mechanism (HTTP/2, compression, encryption, etc.).
In this example, we will implement our COBOL program “Hello, World” as a gRPC server.
IDENTIFICATION DIVISION.
PROGRAM-ID. hello.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* Declare program variables
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 RECORD-TYPE.
05 INPUT-NAME PIC X(10).
05 OUTPUT-PARM.
10 PARM1 PIC X(07).
10 PARM2 PIC X(10).
PROCEDURE DIVISION USING RECORD-TYPE.
MOVE "Hello," TO PARM1.
IF INPUT-NAME IS EQUAL TO (SPACES OR LOW-VALUES)
MOVE "World" TO PARM2
MOVE 2 TO RETURN-CODE
ELSE
MOVE INPUT-NAME TO PARM2
MOVE 0 TO RETURN-CODE
END-IF.
GOBACK.
Create a directory structure with the following contents:
├── d8grpc
│ └── hello_client
│ └── hello_server
│ └── hello
│ go.mod
│ go.sum
The next step is to create the proto message that will be used to expose the COBOL program’s COPYBOOK. To do this, create a file named hello.proto in the d8grpc/hello directory and copy the following file.
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8grpc/hello";
package hello;
// d8grpc hello service definition.
service D8grpc {
// Sends a greeting
rpc Hello (MsgReq) returns (MsgRes) {}
}
// The request message containing the user's name.
message MsgReq {
string hello_name = 1;
}
// The response message containing the greetings
message MsgRes {
string response = 1;
}
The fields of the COBOL COPYBOOK:
- INPUT NAME
- OUTPUT-PARM
Are defined as type CHAR (with lengths of 10 and 17) and are converted to string.
To compile the protocol message, execute the following command:
protoc --go_out=. --go_opt=paths=source_relative \
--go-grpc_out=. --go-grpc_opt=paths=source_relative \
hello/hello.proto
First, install the proto-message compiler utility for the Go language.
To do this, follow these [instructions] (https://grpc.io/docs/protoc-installation/)
Let’s create the gRPC server that will make the call to the COBOL subroutine, in this case the call will be made dynamically. Create the file main.go in the directory d8grpc/hello_server and copy the following file.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
static void* allocArgv(int argc) {
return malloc(sizeof(char *) * argc);
}
*/
import "C"
import (
"context"
"errors"
"flag"
"fmt"
"log"
"net"
"time"
"unsafe"
pb "github.com/driver8soft/examples/d8grpc/hello"
"google.golang.org/grpc"
)
var (
port = flag.Int("port", 50051, "The server port")
)
type server struct {
pb.UnimplementedD8GrpcServer
}
func (s *server) Hello(ctx context.Context, in *pb.MsgReq) (out *pb.MsgRes, err error) {
start := time.Now()
// define argc, argv
c_argc := C.int(1)
c_argv := (*[0xfff]*C.char)(C.allocArgv(c_argc))
defer C.free(unsafe.Pointer(c_argv))
c_argv[0] = C.CString(in.GetHelloName())
// check COBOL program
n := C.cob_resolve(C.CString("hello"))
if n == nil {
err := errors.New("COBOL: program not found")
log.Println(err)
return &pb.MsgRes{}, err
}
//Call COBOL program
log.Println("INFO: program hello started")
ret := C.cob_call(C.CString("hello"), c_argc, (*unsafe.Pointer)(unsafe.Pointer(c_argv)))
log.Printf("INFO: program hello return-code %v", ret)
//COBOL COPYBOOK is converted to Go String using COPYBOOK length
output := C.GoStringN(c_argv[0], 27)
elapsed := time.Since(start)
log.Printf("INFO: Hello elapsed time %s", elapsed)
return &pb.MsgRes{Response: output[9:]}, nil
}
func main() {
flag.Parse()
// d8 Initialize gnucobol
C.cob_init(C.int(0), nil)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("ERROR: failed to listen: %v", err)
}
var opts []grpc.ServerOption
grpcServer := grpc.NewServer(opts...)
pb.RegisterD8GrpcServer(grpcServer, &server{})
log.Printf("INFO: server listening at %v", lis.Addr())
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("ERROR: failed to serve: %v", err)
}
}
Compile the COBOL subroutine with the following command. The result will be a module (shared library) that we can call dynamically from the Go gRPC server using cgo.
cobc -m hello.cbl
The resulting file (*.so, *.dylib) can be left in the d8grpc/hello_server directory.
If you decide to leave the COBOL module in another directory, remember to define it (export COB_LIBRARY_PATH=/…my_library…/).
Open a terminal and start the gRPC server with the following command
go run .
Finally, we will create a Go client to invoke our gRPC COBOL service. Create a main.go file in the d8grpc/hello_client directory and copy the following file.
package main
import (
"context"
"flag"
"log"
pb "github.com/driver8soft/examples/d8grpc/hello"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
var (
addr = flag.String("addr", "localhost:50051", "the address to connect to")
)
var (
name = flag.String("name", "", "name")
)
func main() {
flag.Parse()
// Set up a connection to the server.
conn, err := grpc.NewClient(*addr, grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewD8GrpcClient(conn)
// Contact the server and print out its response.
r, err := client.Hello(context.Background(), &pb.MsgReq{HelloName: *name})
if err == nil {
log.Printf("Output: %s", r.GetResponse())
} else {
log.Printf("ERROR: %v", err)
}
}
To test our COBOL gRPC service, open a new terminal and run the following command.
go run main.go -name=Hooper
3.3 - Playing with PostgreSQL
A COBOL PostgreSQL example.
Is COBOL only valid for accessing DB2?
In this simple example, we will access a PostgreSQL database from a COBOL program.
Your programs can be precompiled (EXEC SQL) to access various SQL databases
- Oracle Pro*Cobol
- IBM DB2 Cobol precompiler
- OpenESQL (PostgreSQL)
To run this program, you need to install PostgreSQL and create the sample database (dvdrental). Instructions on how to do this can be found here.
*****************************************************************
* Connect and get data from PostgreSQL
* Sample DB "dvdrental" table "actor"
*****************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. pgcobol.
AUTHOR.
DATA DIVISION.
WORKING-STORAGE SECTION.
* CONNECT TO POSGRESQL
01 CONN-STR.
05 FILLER PIC X(20) VALUE "dbname=dvdrental ".
05 FILLER PIC X(20) VALUE "user=XXXXXXXX ".
05 FILLER PIC X(20) VALUE "password=XXXXXXX ".
05 FILLER PIC X(20) VALUE "host=localhost ".
05 FILLER PIC X(20) VALUE "port=5432 ".
05 FILLER PIC X(20) VALUE "sslmode=disable ".
05 FILLER PIC X(01) VALUE LOW-VALUES.
01 CONNECTION USAGE POINTER.
01 CONN-STATUS USAGE BINARY-LONG.
* DECLARE CURSOR
01 SQL-QUERY.
05 SQL-QUERY-DATA PIC X(4096) VALUE SPACES.
05 FILLER PIC X(01) VALUE LOW-VALUES.
01 DB-CURSOR USAGE POINTER.
* SQL ERROR
01 SQL-STATUS USAGE BINARY-LONG.
01 SQL-ERROR-PTR USAGE POINTER.
01 SQL-ERROR-STR PIC X(4096) BASED.
01 SQL-ERROR-MSG PIC X(100) VALUE SPACES.
* COUNTER
01 ROW-COUNTER USAGE BINARY-LONG.
01 COLUMN-COUNTER USAGE BINARY-LONG.
* FETCH
01 RESULT-PTR USAGE POINTER.
01 RESULT-STR PIC X(4096) BASED.
01 RESULT-DATA PIC X(4096) VALUE SPACES.
01 TABLE-ROW.
02 actor_id PIC 9(4) VALUE ZEROS.
02 first_name PIC X(45) VALUE SPACES.
02 last_name PIC X(45) VALUE SPACES.
02 last_update PIC X(22) VALUE SPACES.
* AUX VARIABLES
01 DB-ROW PIC 9(7) VALUE ZEROS.
01 DB-COLUMN PIC 9(3) VALUE ZEROS.
*> *********************************************************************
PROCEDURE DIVISION.
PERFORM CONNECT-DB.
MOVE "SELECT actor_id, first_name, " &
"last_name, last_update " &
"FROM actor;"
TO SQL-QUERY-DATA.
PERFORM DECLARE-CURSOR.
PERFORM ROW-COUNT.
PERFORM COLUMN-COUNT.
* ITERATE OVER ROWS
PERFORM VARYING DB-ROW FROM 0 BY 1
UNTIL DB-ROW >= ROW-COUNTER
PERFORM VARYING DB-COLUMN FROM 0 BY 1
UNTIL DB-COLUMN >= COLUMN-COUNTER
PERFORM ROW-FETCH
END-PERFORM
DISPLAY actor_id " - "
first_name " - "
last_name " - "
last_update
END-PERFORM.
PERFORM DISCONNECT.
GOBACK.
*
CONNECT-DB.
* CONNECT AND CHECK DB STATUS
CALL "PQconnectdb" USING CONN-STR
RETURNING CONNECTION.
CALL "PQstatus" USING BY VALUE CONNECTION
RETURNING CONN-STATUS.
IF CONN-STATUS NOT EQUAL 0 THEN
DISPLAY "Connection error! " CONN-STATUS
STOP RUN
END-IF.
DISCONNECT.
* CLOSE CONNECTION DB
CALL "PQfinish" USING BY VALUE CONNECTION
RETURNING OMITTED.
DECLARE-CURSOR.
* OPEN CURSOR
CALL "PQexec" USING BY VALUE CONNECTION
BY REFERENCE SQL-QUERY
RETURNING DB-CURSOR END-CALL.
CALL "PQresultStatus" USING BY VALUE DB-CURSOR
RETURNING SQL-STATUS.
CALL "PQresStatus" USING BY VALUE SQL-STATUS
RETURNING SQL-ERROR-PTR.
SET ADDRESS OF SQL-ERROR-STR TO SQL-ERROR-PTR.
STRING SQL-ERROR-STR DELIMITED BY x"00"
INTO SQL-ERROR-MSG
END-STRING.
IF SQL-STATUS NOT EQUAL 2 THEN
DISPLAY "Open Cursor error! " SQL-STATUS SQL-ERROR-MSG
STOP RUN
END-IF.
DISPLAY "sql_status: " SQL-STATUS
" sql_error: " SQL-ERROR-MSG.
ROW-COUNT.
* GET NUMBER OF ROWS
CALL "PQntuples" USING BY VALUE DB-CURSOR
RETURNING ROW-COUNTER.
DISPLAY "number of rows: " ROW-COUNTER.
COLUMN-COUNT.
* GET NUMBER OF COLUMNS
CALL "PQnfields" USING BY VALUE DB-CURSOR
RETURNING COLUMN-COUNTER.
DISPLAY "number of fields: " COLUMN-COUNTER.
ROW-FETCH.
*> FETCH
CALL "PQgetvalue" USING BY VALUE DB-CURSOR
BY VALUE DB-ROW BY VALUE DB-COLUMN
RETURNING RESULT-PTR END-CALL
SET ADDRESS OF RESULT-STR TO RESULT-PTR
INITIALIZE RESULT-DATA.
STRING RESULT-STR DELIMITED BY x"00"
INTO RESULT-DATA END-STRING.
EVALUATE DB-COLUMN
WHEN 0
MOVE RESULT-DATA TO actor_id
WHEN 1
MOVE RESULT-DATA TO first_name
WHEN 2
MOVE RESULT-DATA TO last_name
WHEN 3
MOVE RESULT-DATA TO last_update
END-EVALUATE.
Remember to modify the WORKING CONN-STR fields with a valid username and password for the database connection
The functions used by the COBOL program require the PostgreSQL library ’libpq’, find out where this library is installed and add it when compiling the program, for example:
cobc -x pgcobol.cbl -L/Library/postgreSQL/16/lib -lpq
3.4 - Calling COBOL containers
Call remote COBOL programs.
Similar to the CICS mechanism for calling remote programs (EXEC CICS LINK), you can make calls between COBOL programs deployed in different containers.
The following is a graphical description of the execution flow
loanmain.cbl <–> d8link.go <———————–> main.go <–> loancalc.cbl
- The COBOL program loanmain.cbl makes a CALL to the gRPC connector d8link, which simulates an EXEC CICS LINK statement:
- The program to be called
- The data exchange area (COMMAREA)
- And the length of the COMMAREA
- The gRPC connector d8link receives the data (COMMAREA) and calls the corresponding COBOL microservice.
- The gPRC controller (main.go) handles the protocol message, converts it to a compatible structure and calls the COBOL program loancalc.cbl.
- The COBOL program updates the data area and returns control to the gRPC controller.
- The data is sent back to the d8link connector, which copies it into the memory area defined by the COBOL program.
Create a directory structure like this
├── d8link
│ └── link_client
│ └── link_server
│ └── link
│ go.mod
│ go.sum
In the link directory we will define our proto message (link.proto).
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8link/link";
package link;
// The Link service definition.
service LinkService {
rpc CommArea (CommReq) returns (CommResp) {}
}
// The request message containing program to link, commarea and commarea length.
message CommReq {
string link_prog = 1;
int32 comm_len = 2;
bytes input_msg = 3;
}
// The response message containing commarea
message CommResp {
bytes output_msg = 1;
}
Next, we will create the d8link.go program in the link_client directory.
package main
/*
#include <string.h>
#include <stdlib.h>
*/
import "C"
import (
"context"
"flag"
"log"
"unsafe"
pb "github.com/driver8soft/examples/d8link/link"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
var (
addr = flag.String("addr", "localhost:50051", "the address to connect to")
)
//export D8link
func D8link(c_program *C.char, c_commarea *C.char, c_commlen *C.int) C.int {
flag.Parse()
// C variables to Go variables
program := C.GoStringN(c_program, 8) // max length of COBOL mainframe program = 8
commarea := C.GoBytes(unsafe.Pointer(c_commarea), *c_commlen)
commlen := int32(*c_commlen)
log.Println("INFO: Call program -", program)
// Set up a connection to the server.
conn, err := grpc.NewClient(*addr, grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewLinkServiceClient(conn)
// Contact the server
r, err := client.CommArea(context.Background(), &pb.CommReq{LinkProg: program, CommLen: commlen, InputMsg: commarea})
if err != nil {
log.Fatalf("ERROR: calling program - %s - %v", program, err)
}
outMsg := r.GetOutputMsg()
C.memcpy(unsafe.Pointer(c_commarea), unsafe.Pointer(&outMsg[0]), C.size_t(commlen))
return 0
}
func main() {
}
We are going to export the D8link function so that it can be called from a COBOL program, to do this it is necessary to compile it using the c-shared option of Go.
The Go compiler will generate an object (D8link.dylib D8link.so) and a file (D8link.h) that will be called dynamically from the COBOL code.
Finally, we will create the gRPC server (main.go) in the link_server directory, which will be in charge of receiving the proto message and calling the target COBOL program.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
static void* allocArgv(int argc) {
return malloc(sizeof(char *) * argc);
}
*/
import "C"
import (
"context"
"flag"
"fmt"
"log"
"net"
"strings"
"time"
"unsafe"
pb "github.com/driver8soft/examples/d8link/link"
"google.golang.org/grpc"
)
var (
port = flag.Int("port", 50051, "The server port")
)
type server struct {
pb.UnimplementedLinkServiceServer
}
func (s *server) CommArea(ctx context.Context, in *pb.CommReq) (out *pb.CommResp, err error) {
start := time.Now()
// remove trailing spaces from program name
program := strings.TrimSpace(in.GetLinkProg())
c_program := C.CString(program)
defer C.free(unsafe.Pointer(c_program))
c_commlen := C.int(in.GetCommLen())
// allocate argc & argv variables
c_argc := C.int(1)
c_argv := (*[0xfff]*C.char)(C.allocArgv(c_argc))
defer C.free(unsafe.Pointer(c_argv))
c_argv[0] = C.CString(string(in.GetInputMsg()))
defer C.free(unsafe.Pointer(c_argv[0]))
// check COBOL program
n := C.cob_resolve(c_program)
if n == nil {
log.Println("ERROR: Module not found. Program name =", program)
} else {
log.Printf("INFO: %s started", program)
ret := C.cob_call(c_program, c_argc, (*unsafe.Pointer)(unsafe.Pointer(c_argv)))
log.Printf("INFO: %s return-code %v", program, ret)
}
c_msg_output := C.GoStringN(c_argv[0], c_commlen)
elapsed := time.Since(start)
log.Printf("INFO: %s elapsed time %s", program, elapsed)
return &pb.CommResp{OutputMsg: []byte(c_msg_output)}, nil
}
func main() {
flag.Parse()
// d8 Initialize gnucobol
C.cob_init(C.int(0), nil)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("ERROR: failed to listen: %v", err)
}
grpcServer := grpc.NewServer()
pb.RegisterLinkServiceServer(grpcServer, &server{})
log.Printf("INFO: server listening at %v", lis.Addr())
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("ERROR: failed to serve: %v", err)
}
}
Try to make remote calls between COBOL programs by exchanging a data area (COPYBOOK). To do this, remember that
- The calling program must be compiled to produce an executable (option -x GNUCobol).
- The called program must be compiled to produce a shared library (option -m GNUCobol).
- Both programs must be compiled with the same byte order to share binary data.
- To simplify testing, COBOL programs can be located in the directories defined above (link_client link_server).
You can use the example COBOL programs loanmain.cbl and loancalc.cbl.
******************************************************************
*
* Loan Calculator Main Program
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loanmain.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 PROG-NAME PIC X(8) VALUE "loancalc".
01 COMMLEN PIC 9(9) COMP.
01 COMMAREA.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION.
* code goes here!
INITIALIZE COMMAREA.
DISPLAY "Compound Interest Calculator"
DISPLAY "Principal amount: " WITH NO ADVANCING.
ACCEPT PRIN-AMT.
DISPLAY "Interest rate: " WITH NO ADVANCING.
ACCEPT INT-RATE.
DISPLAY "Number of years: " WITH NO ADVANCING.
ACCEPT TIMEYR.
COMPUTE COMMLEN = LENGTH OF COMMAREA.
CALL "D8link" USING PROG-NAME COMMAREA COMMLEN.
DISPLAY "Error Msg: " ERROR-MSG.
DISPLAY "Couta: " PAYMENT.
GOBACK.
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
DISPLAY "PRIN-AMT: " PRIN-AMT.
DISPLAY "INT-RATE: " INT-RATE.
DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
DISPLAY "PAYMENT: " PAYMENT.
DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
3.5 - COBOL & Kafka
Turn your COBOL program into a Kafka consumer/producer.
Leverage your COBOL programs into an event-driven process model.
Learn how to convert a COBOL program into a Kafka consumer/producer.
From the COBOL program, we will make a call to the D8kafka module and pass it:
- The Kafka topic
- A comma-separated list of values (key : value)
******************************************************************
*
* Loan kafka producer
* ==========================
*
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. cuotak.
ENVIRONMENT DIVISION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
01 WS-LOAN.
05 WS-AMT PIC 9(7)V9(2).
05 WS-INT PIC 9(2)V9(2).
05 WS-YEAR PIC 9(2).
******************************************************************
01 KAFKA.
05 KAFKA-TOPIC PIC X(05) VALUE "loans".
05 FILLER PIC X(1) VALUE LOW-VALUES.
05 KAFKA-KEY.
10 KAFKA-KEY1 PIC X(15) VALUE "PrincipalAmount".
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-KEY2 PIC X(12) VALUE "InterestRate".
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-KEY1 PIC X(09) VALUE "TimeYears".
10 FILLER PIC X(1) VALUE LOW-VALUES.
05 KAFKA-VALUE.
10 KAFKA-AMT-VALUE PIC zzzzzz9.99.
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-INT-VALUE PIC z9.99.
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-YEAR-VALUE PIC zz.
10 FILLER PIC X(1) VALUE LOW-VALUES.
PROCEDURE DIVISION.
INITIALIZE WS-LOAN.
DISPLAY "Amount: " WITH NO ADVANCING.
ACCEPT WS-AMT.
DISPLAY "Interest: " WITH NO ADVANCING.
ACCEPT WS-INT.
DISPLAY "Number of Years: " WITH NO ADVANCING.
ACCEPT WS-YEAR.
MOVE WS-AMT TO KAFKA-AMT-VALUE.
MOVE WS-INT TO KAFKA-INT-VALUE.
MOVE WS-YEAR TO KAFKA-YEAR-VALUE.
CALL "D8kafka" USING KAFKA-TOPIC
KAFKA-KEY
KAFKA-VALUE.
DISPLAY "Return-code: " RETURN-CODE.
GOBACK.
A simplified example of d8kafka is shown below.
package main
/*
#include <string.h>
#include <stdlib.h>
*/
import "C"
import (
"encoding/json"
"fmt"
"os"
"strings"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
type Kdata struct {
Key string `json:"key"`
Value string `json:"value"`
}
//export D8kafka
func D8kafka(c_topic *C.char, c_key *C.char, c_value *C.char) C.int {
keys := strings.Split(C.GoString(c_key), ",")
values := strings.Split(C.GoString(c_value), ",")
data := make([]Kdata, len(keys))
for i := 0; i < len(keys); i++ {
data[i] = Kdata{Key: keys[i], Value: values[i]}
}
KafkaMsg, _ := json.Marshal(data)
topic := C.GoString(c_topic)
p, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:29092",
"client.id": "client",
"acks": "all"},
)
if err != nil {
fmt.Printf("ERROR: Failed to create producer: %s\n", err)
os.Exit(1)
}
delivery_chan := make(chan kafka.Event, 1000)
err = p.Produce(
&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(KafkaMsg),
},
delivery_chan,
)
if err != nil {
fmt.Printf("ERROR: Failed to produce message: %s\n", err)
os.Exit(1)
}
e := <-delivery_chan
m := e.(*kafka.Message)
if m.TopicPartition.Error != nil {
fmt.Printf("ERROR: Delivery failed: %v\n", m.TopicPartition.Error)
} else {
fmt.Printf("INFO: Delivered message to topic %s [%d] at offset %v\n",
*m.TopicPartition.Topic, m.TopicPartition.Partition, m.TopicPartition.Offset)
}
close(delivery_chan)
return 0
}
func main() {
}
To consume the kafka topic from a Go program you can use the following example:
package main
import (
"fmt"
"os"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var topic string = "loans"
var run bool = true
func main() {
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:29092",
"group.id": "sample",
"auto.offset.reset": "smallest"},
)
if err != nil {
fmt.Printf("ERROR: Failed to create consumer: %s\n", err)
os.Exit(1)
}
err = consumer.Subscribe(topic, nil)
if err != nil {
fmt.Printf("ERROR: Failed to subscribe: %s\n", err)
os.Exit(1)
}
for run {
ev := consumer.Poll(100)
switch e := ev.(type) {
case *kafka.Message:
fmt.Printf("INFO: %s", e.Value)
case kafka.Error:
fmt.Printf("%% ERROR: %v\n", e)
run = false
}
}
consumer.Close()
}
You must have Kafka installed to run a test.
An easy way to do this is to use Docker (docker-compose.yml) to set up a minimal test environment with Zookeeper and Kafka.
3.6 - JCL to DAG
How to convert a JCL into a configuration file in order to run a batch program.
We are going to convert a JCL step into a configuration file (yaml).
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=BCUOTA
//INFILE DD DSN=DEV.APPL1.TEST,DISP=SHR
//OUTFILE DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*Create a step.yaml file and copy and paste the following code into it.
---
stepname: "step1"
exec:
pgm: "bcuota"
dd:
- name: "infile"
dsn: "test.txt"
disp: "shr"
normaldisp: "catlg"
abnormaldisp: "catlg"
- name: "outfile"
dsn: "cuota.txt"
disp: "new"
normaldisp: "catlg"
abnormaldisp: "delete"Next, using this configuration yaml, we will run a batch file read/write program. The main program bcuota.cbl reads an input file, calls the COBOL routine loancalc.cbl to calculate the loan quota, and writes the result to the output file.
******************************************************************
*
* Loan Calculator Batch
* ==========================
*
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. bcuota.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT LOAN ASSIGN TO "infile"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
SELECT CUOTA ASSIGN TO "outfile"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD LOAN.
01 LOAN-FILE PIC X(26).
FD CUOTA.
01 CUOTA-FILE.
05 CUOTA-ACC PIC X(10).
05 CUOTA-PAY PIC 9(7)V9(2).
WORKING-STORAGE SECTION.
01 WS-LOAN.
05 WS-ACC PIC X(10).
05 FILLER PIC X(1).
05 WS-AMT PIC 9(7).
05 FILLER PIC X(1).
05 WS-INT PIC 9(2)V9(2).
05 FILLER PIC X(1).
05 WS-YEAR PIC 9(2).
01 WS-EOF PIC X(1) VALUE "N".
01 WS-COUNTER PIC 9(9) VALUE ZEROES.
****************************************************************
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION.
OPEN INPUT LOAN.
OPEN OUTPUT CUOTA.
PERFORM UNTIL WS-EOF='Y'
READ LOAN INTO WS-LOAN
AT END MOVE 'Y' TO WS-EOF
NOT AT END
MOVE WS-AMT TO PRIN-AMT
MOVE WS-INT TO INT-RATE
MOVE WS-YEAR TO TIMEYR
CALL "loancalc" USING LOAN-PARAMS
ADD 1 TO WS-COUNTER
MOVE WS-ACC TO CUOTA-ACC
MOVE PAYMENT TO CUOTA-PAY
WRITE CUOTA-FILE
END-WRITE
END-READ
END-PERFORM.
CLOSE LOAN.
CLOSE CUOTA.
DISPLAY "TOTAL RECORDS PROCESSED: " WS-COUNTER.
GOBACK.
The loancalc.cbl routine has been modified to avoid writing to the system log.
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
* DISPLAY "PRIN-AMT: " PRIN-AMT.
* DISPLAY "INT-RATE: " INT-RATE.
* DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
* DISPLAY "PAYMENT: " PAYMENT.
* DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
Compile both programs to create a shared library (*.so, *dylib).
cobc -m bcouta.cbl loancalc.cbl.
The d8parti controller will replace the JES mainframe subsystem, here is a simplified version of this module, create a d8parti.go file and copy the following code.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
*/
import "C"
import (
"fmt"
"log"
"os"
"time"
"unsafe"
"github.com/spf13/viper"
)
type step struct {
Stepname string `mapstructure:"stepname"`
Exec exec
Dd []dd
}
type exec struct {
Pgm string `mapstructure:"pgm"`
}
type dd struct {
Name string `mapstructure:"name"`
Dsn string `mapstructure:"dsn"`
Disp string `mapstructure:"disp"`
Normaldisp string `mapstructure:"normaldisp"`
Abnormaldisp string `mapstructure:"abnormaldisp"`
}
var Step *step
func config() error {
// Read yaml config file
viper.SetConfigName("step")
viper.SetConfigType("yaml")
viper.AddConfigPath(".")
if err := viper.ReadInConfig(); err != nil {
return err
}
// Unmarshal yaml config file
if err := viper.Unmarshal(&Step); err != nil {
return err
}
// Create Symlink
for i := 0; i < len(Step.Dd); i++ {
err := os.Symlink(Step.Dd[i].Dsn, Step.Dd[i].Name)
if err != nil {
switch {
case os.IsExist(err):
// DDNAME already exist
log.Printf("INFO: DDNAME=%s already exists. %s", Step.Dd[i].Name, err)
case os.IsNotExist(err):
// DDNAME invalid
log.Printf("ERROR: DDNAME=%s invalid ddname. %s", Step.Dd[i].Name, err)
return err
default:
log.Println(err)
return err
}
}
}
return nil
}
func cobCall(p string) error {
defer delSymlink()
c_progName := C.CString(p)
defer C.free(unsafe.Pointer(c_progName))
n := C.cob_resolve(c_progName)
if n == nil {
return fmt.Errorf("ERROR: Program %s not found", p)
} else {
log.Printf("INFO: PGM=%s started", p)
r := C.cob_call_with_exception_check(c_progName, C.int(0), nil)
rc := int(C.cob_last_exit_code())
err := C.GoString(C.cob_last_runtime_error())
switch int(r) {
case 0:
log.Printf("INFO: program %s exited with return-code: %v", p, rc)
C.cob_tidy()
case 1:
log.Printf("INFO: program %s STOP RUN with return-code: %v", p, rc)
case -1:
return fmt.Errorf("ERROR: program %s exit with return-code: %v and error: %s", p, rc, err)
case -2:
return fmt.Errorf("FATAL: program %s exit with return-code: %v and error: %s", p, rc, err)
case -3:
return fmt.Errorf("ERROR: program %s signal handler exit with signal: %v and error: %s", p, rc, err)
default:
return fmt.Errorf("ERROR: program %s unexpected return exit code: %v and error: %s", p, rc, err)
}
return nil
}
}
func delSymlink() {
for i := 0; i < len(Step.Dd); i++ {
err := os.Remove(Step.Dd[i].Name)
if err != nil {
log.Printf("INFO: DDNAME=%s does not exists. %s", Step.Dd[i].Name, err)
}
}
}
func main() {
start := time.Now()
// Initialize gnucobol
C.cob_init(C.int(0), nil)
log.Println("INFO: gnucobol initialized")
// Load config file
if err := config(); err != nil {
log.Printf("ERROR: reading yaml config file. %s", err)
os.Exit(12)
}
// Call COBOL program -> EXEC PGM defined in JCL
if err := cobCall(Step.Exec.Pgm); err != nil {
log.Println(err)
os.Exit(12)
}
elapsed := time.Since(start)
log.Printf("INFO: %s elapsed time %s", Step.Exec.Pgm, elapsed)
}
How do I create a sample input file (infile)?
The input file format is very simple.
01 WS-LOAN.
05 WS-ACC PIC X(10).
05 FILLER PIC X(1).
05 WS-AMT PIC 9(7).
05 FILLER PIC X(1).
05 WS-INT PIC 9(2)V9(2).
05 FILLER PIC X(1).
05 WS-YEAR PIC 9(2).
An account number (10 bytes), an amount (7 bytes), an interest rate (4 bytes with two decimal places) and a period of time in years (2 bytes). The fields are delimited by a separator (FILLER 1 byte) to make the input file easier to read.
You can use the following example program to create the input file.
package main
import (
"flag"
"fmt"
"math/rand"
"os"
"strconv"
"time"
)
var r1 *rand.Rand
var (
rows = flag.Int("rows", 1000, "number of rows to generate")
)
var (
file = flag.String("file", "test.txt", "input file name")
)
func main() {
flag.Parse()
s1 := rand.NewSource(time.Now().UnixNano())
r1 = rand.New(s1)
f, err := os.Create(*file)
if err != nil {
fmt.Println(err)
return
}
for i := 0; i != *rows; i++ {
output := account(i) + "-" + amount() + "-" + interest() + "-" + yearsPending() + "\n"
_, err := f.WriteString(output)
if err != nil {
fmt.Println(err)
f.Close()
return
}
}
err = f.Close()
if err != nil {
fmt.Println(err)
return
}
}
func account(id int) string {
return "id:" + fmt.Sprintf("%07d", id+1)
}
func amount() string {
min := 1000
max := 1000000
a := strconv.Itoa(r1.Intn(max-min+1) + min)
for i := len(a); i != 7; i++ {
a = "0" + a
}
return a
}
func interest() string {
return "0450"
}
func yearsPending() string {
min := 5
max := 25
y := strconv.Itoa(r1.Intn(max-min+1) + min)
if len(y) < 2 {
y = "0" + y
}
return y
}
3.7 - COBOL to Go
How to convert COBOL code to Go.
Advances in AI Gen offer a glimpse of a future where code conversion between different programming languages can be done automatically and transparently.
However, the characteristics of the COBOL language must be taken into account in order to select an option that preserves the converted code structure so that it can continue to be maintained by the team in charge.
Let us take the example of a COBOL routine that calculates the instalment of a loan.
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
DISPLAY "PRIN-AMT: " PRIN-AMT.
DISPLAY "INT-RATE: " INT-RATE.
DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
DISPLAY "PAYMENT: " PAYMENT.
DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
A first approach is to preserve the structure of the COBOL code:
- A COBOL subroutine is equivalent to a Go function.
- The variables defined in the WORKING STORAGE are grouped and converted into Go variables.
- The PROCEDURE DIVISION code is made up of one or more sections (PARAGRAPHS), which in turn can be transformed into very simple functions.
- Finally, the LINKAGE SECTION variables define the parameters of the main function and are shared (pointers) between all the functions.
// Declare variables in the working storage section
var (
WS_ERROR string
WS_MSG00 string = "OK"
WS_MSG10 string = "INVALID INT. RATE"
WS_MSG12 string = "INVALID NUMBER YEARS"
MONTHLY_RATE float64
AUX_X float64
AUX_Y float64
AUX_Z float64
)
// Data to share with COBOL subroutines
type LoanParams struct {
PrinAmt float64
IntRate float64
TimeYr int32
Payment float64
ErrorMsg string
}
func loancalc(amount float64, interest float64, nyears int32) (payment float64, errmsg string) {
WS_ERROR = "N"
loanParams := LoanParams{
PrinAmt: amount,
IntRate: interest,
TimeYr: nyears,
}
fmt.Println("PRIN-AMT:", loanParams.PrinAmt)
fmt.Println("INT-RATE:", loanParams.IntRate)
fmt.Println("TIMEYR:", loanParams.TimeYr)
initial(&loanParams)
if WS_ERROR == "N" {
process(&loanParams)
}
wrapup(&loanParams)
return loanParams.Payment, loanParams.ErrorMsg
}
func initial(loanParams *LoanParams) {
if loanParams.IntRate <= 0 {
loanParams.ErrorMsg = WS_MSG10
WS_ERROR = "Y"
} else {
if loanParams.TimeYr <= 0 {
loanParams.ErrorMsg = WS_MSG12
WS_ERROR = "Y"
}
}
}
func process(loanParams *LoanParams) {
MONTHLY_RATE = loanParams.IntRate / 12 / 100
AUX_X = math.Pow((1 + MONTHLY_RATE), float64(loanParams.TimeYr*12))
AUX_Y = AUX_X * MONTHLY_RATE
AUX_Z = (AUX_X - 1) / AUX_Y
loanParams.Payment = loanParams.PrinAmt / AUX_Z
loanParams.ErrorMsg = WS_MSG00
}
func wrapup(loanParams *LoanParams) {
fmt.Println("PAYMENT:", loanParams.Payment)
fmt.Println("ERROR-MSG:", loanParams.ErrorMsg)
}
With gRPC, the COBOL code has already been exposed through a standard interface that defines the input/output parameters of the function (e.g. through a proto message).
By defining such an interface, it is possible to refactor the code, simplifying the end result.
func loancalc(amount, interest float64, nyears int32) (payment float64, errmsg string) {
if interest <= 0 {
return 0, "Invalid int. rate"
}
if nyears <= 0 {
return 0, "Invalid number of years"
}
monthlyRate := (interest / 12 / 100)
x := math.Pow((1 + monthlyRate), float64(nyears*12))
y := x * monthlyRate
payment = amount / ((x - 1) / y)
return payment, "OK"
}
3.8 - Python
Is Python your language of choice?
The gRPC technology allows us to easily connect programs written in different programming languages.
In this example, we will create a Python client to call our gRPC COBOL service (hello.cbl).
To do this, we first need to compile the proto-message for the Python language.
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8grpc/hello";
package hello;
// d8grpc hello service definition.
service D8grpc {
// Sends a greeting
rpc Hello (MsgReq) returns (MsgRes) {}
}
// The request message containing the user's name.
message MsgReq {
string hello_name = 1;
}
// The response message containing the greetings
message MsgRes {
string response = 1;
}
Install the compiler for the Python language and run the following command
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. hello.proto
Compiling the proto file will create the necessary stubs for our Python client.
- hello_pb2.py
- hello_pb2_grpc.py
Next, create a client.py file and copy the following code.
import grpc
import hello_pb2
import hello_pb2_grpc
def run(inputname):
with grpc.insecure_channel('localhost:50051') as channel:
stub = hello_pb2_grpc.D8grpcStub(channel)
r = stub.Hello(hello_pb2.MsgReq(hello_name=inputname))
print(f"Result: {r.response}")
if __name__ == '__main__':
# Get user Input
inputname = input("Please enter name: ")
run(inputname)
To test the new Python client, open a terminal and run
python client.py
Easy come, easy Go, easy Python, …
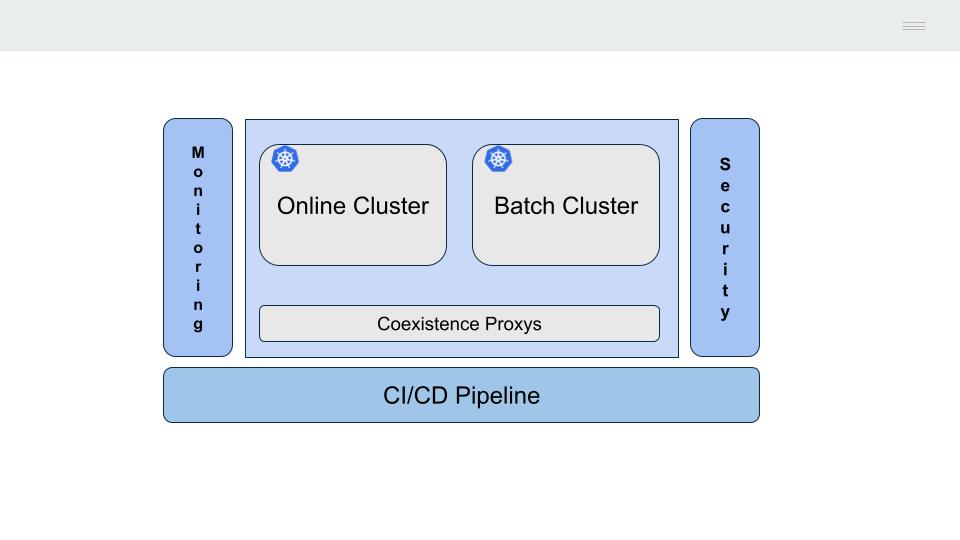
4 - Concepts
How to dismantle an IBM mainframe … and not die trying
An IBM mainframe server is designed as a highly coupled monolithic architecture. Application programs communicate with each other and with data repositories by exchanging memory addresses (pointers).
How is it possible to break down this monolith in a step-by-step and secure way so that the risks of the process are minimised?
4.1 - Strangler Fig Pattern
How do you safely break down a monolithic architecture?
The IBM mainframe server is a monolithic system, there is no clear separation between the different levels or layers of the technical architecture, all processes reside on the same machine (CICS, batch, database, etc).
Shared memory is used for communication between the different processes (calls between programs, access to the DB2 database, etc.). This mechanism has the advantage of being very efficient (necessary in the last century when the cost of computing was very high), but the disadvantage of tightly coupling the processes, making it very difficult to update or replace them.
This last characteristic makes the most viable alternative for the progressive migration of the functionality deployed on the mainframe to adopt the model described by Matin Fowler as Strangler Fig.
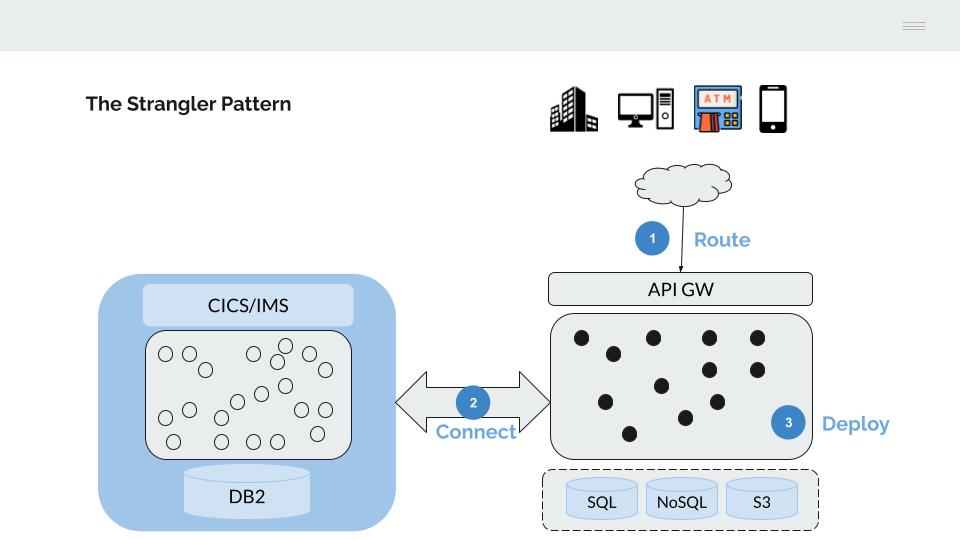
- Traffic from the channels is gradually moved to an API gateway, which is used to route it to the back-end platforms (mainframe or next-generation)
- The two platforms are connected to enable a phased deployment of applications
- Gradually migrate the applications until the IBM mainframe server is emptied of its content
API Gateway
The connection from the channels is progressively routed to an API gateway.
This API gateway has two main functions:
-
On the one hand, we can think of this API Gateway as replacing the functionality provided by the CICS Transactional Monitor, which manages the following:
- The communication (send/receive) with the channels, we will replace the 4-character transaction codes of CICS with well-formed APIs
- The authentication process, replacing CESN/CESF and RACF with a mechanism based on LDAP
- Authorising operations, replacing RACF with a mechanism based on ACLs/RBAC.
-
On the other hand, this API gateway is used to route traffic from the channels to the target platform, gradually replacing IBM mainframe server functionality with equivalent next-generation platform functionality.
Architecture for cross-platform coexistence
In order to enable the progressive deployment of functionality, it is necessary to connect the two platforms. These connection mechanisms are essential to avoid “big bang” deployments, to facilitate rollback in the event of problems, to enable parallel deployments, etc, in short, to minimise the risks inherent in a change process such as this.
There are two basic connection mechanisms
DB2 Proxy
z/DB2 provides several mechanisms for accessing DB2 tables using jdbc and odbc drivers.
This is similar to the functionality provided by CICS when connecting to DB2. The DB2 proxy manages a pool of database connections, the identification/authorisation process and the encryption of traffic.
CICS/IMS Proxy
Allows transactions to be executed over a low-level connection based on TCP/IP sockets.
Deployment of functionality
When migrating mainframe functionality to a cloud architecture, there are three alternatives.
Rebuild
The functionality can be redesigned, written in a modern programming language (java, python, go, …) and deployed as a microservice on the next-gen platform.
These new programs can reuse the mainframe platform through the coexistence architecture described above.
- Execute SQL statements accessing DB2 through the DB2 proxy.
- Call the CICS/IM Proxy to invoke a mainframe transaction.
Refactor
In this case, we are compiling the COBOL mainframe code on the next-generation platform (Linux-x86/arm) and deploying it as a microservice. This is equivalent to any other microservice built in Java, Python, go, etc.
Replace
Invocation of APIs provided by a third-party product that implements the required functionality.
The above alternatives are not exclusive, different alternatives can be chosen for each functionality or mainframe application, but they all share the same technical architecture, the same pipeline for building and deploying and benefit from the advantages offered by the new technical platform (security, encryption, automation, etc.).
4.2 - Microservice model
What microservices model do we need for COBOL?
The model for building microservices must allow:
- The use of different programming languages (including COBOL)
- Be interoperable (with each other and with mainframe logic)
- Migrate data between platforms (mainframe DB2 / next-gen SQL).
To do so, the Hexagonal Architecture will be used as a reference model.
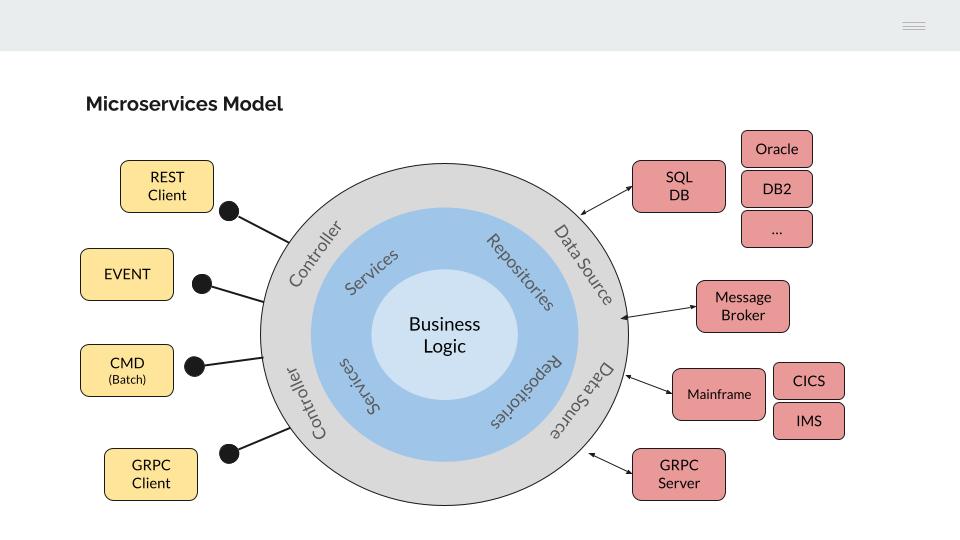
Looking at the left-hand side of the model, the application programs are decoupled from the interface used to execute them. This concept should be familiar as it is the model used to build COBOL applications on an IBM mainframe.
The COBOL language originated in the 1960s when all processing was done in batch. IBM later developed its CICS/IMS transactional monitors to allow COBOL programs to connect to devices in its SNA communications architecture.
COBOL programs only handle data structures (COBOL COPYBOOKS) and it is the transactional monitor that manages the communication interface (LU0, LU2, Sockets, MQSeries, etc.).
Similarly, the business functionality implemented in microservices is independent of the interface used to invoke it through a specific controller.
This allows us to reuse application logic from different interfaces:
- REST API (json)
- gRPC API (proto)
- Events (Kafka consumers)
- Console (batch processes)
- Etc.
COBOL programs are perfectly adapted to this model, only a conversion process from the chosen interface (json / proto) to a COPYBOOK structure is required.
On the right-hand side of the model, the business logic should be agnostic to the infrastructure required for data retrieval.
Although this model has obvious advantages, the level of abstraction and complexity to be introduced in the design and construction of the microservices is high, which leads us to make a partial implementation of the model, focusing on two relevant aspects that provide value;
SQL databases
The mainframe DB2 is accessed through a proxy.
This proxy exposes a gRPC interface to allow calls from microservices written in different programming languages.
The same mechanism is replicated for access to other SQL database managers (e.g. Oracle or PostgreSQL).
Cross-platform data migration (e.g. from DB2 to Oracle) is facilitated by configuring the target data source in the microservice.
Calling CICS/IMS transactions
In this case, CICS/IMS programs are exposed as microservices (http/REST or gRPC), facilitating their subsequent migration as long as the data structure handled by the program does not change.
4.3 - Online Architecture
How do you migrate CICS/IMS transactions to microservices?
The answer should be quite simple, by compiling the COBOL program and deploying the object in a container (e.g. Docker).
However, there are two types of statements in the online programs that are not part of the COBOL language and must be pre-processed:
- The statements of the transactional monitor used (CICS/IMS).
- The access statements to the DB2 database
CICS statatements
Online programs are deployed on a transactional monitor (CICS/IMS) which performs a number of functions that cannot be performed directly using the COBOL programming language.
The main function would be the sending and receiving of messages.
The COBOL language has its origins in the mid-20th century when all processing was done in batch, there were no devices to connect to.
Communication is therefore managed by the transactional monitor. COBOL programs define a fixed data structure (COPYBOOK) and include CICS block statements (EXEC CICS SEND/RECEIVE) as part of their code to send or receive application messages.
The transaction monitor uses the address (pointer) and length of the COPYBOOK to read/write the message to/from it.
The proposed microservices model behaves like CICS/IMS, extending the gRPC/proto capabilities to the COBOL language.
-
COBOL program COPYBOOKs (data in LINKAGE SECTION) used to send/receive messages are converted to proto messages.
-
The gRPC interface (gRPC server) is managed by a special controller
-
The message is converted from proto to COPYBOOK format. The message data (string, int, float, etc.) is transformed to COBOL data (CHAR, DECIMAL, PACKED DECIMAL, etc.)
-
Finally, Go cgo is used to load the COBOL program and execute it by passing the generated data structure to it.
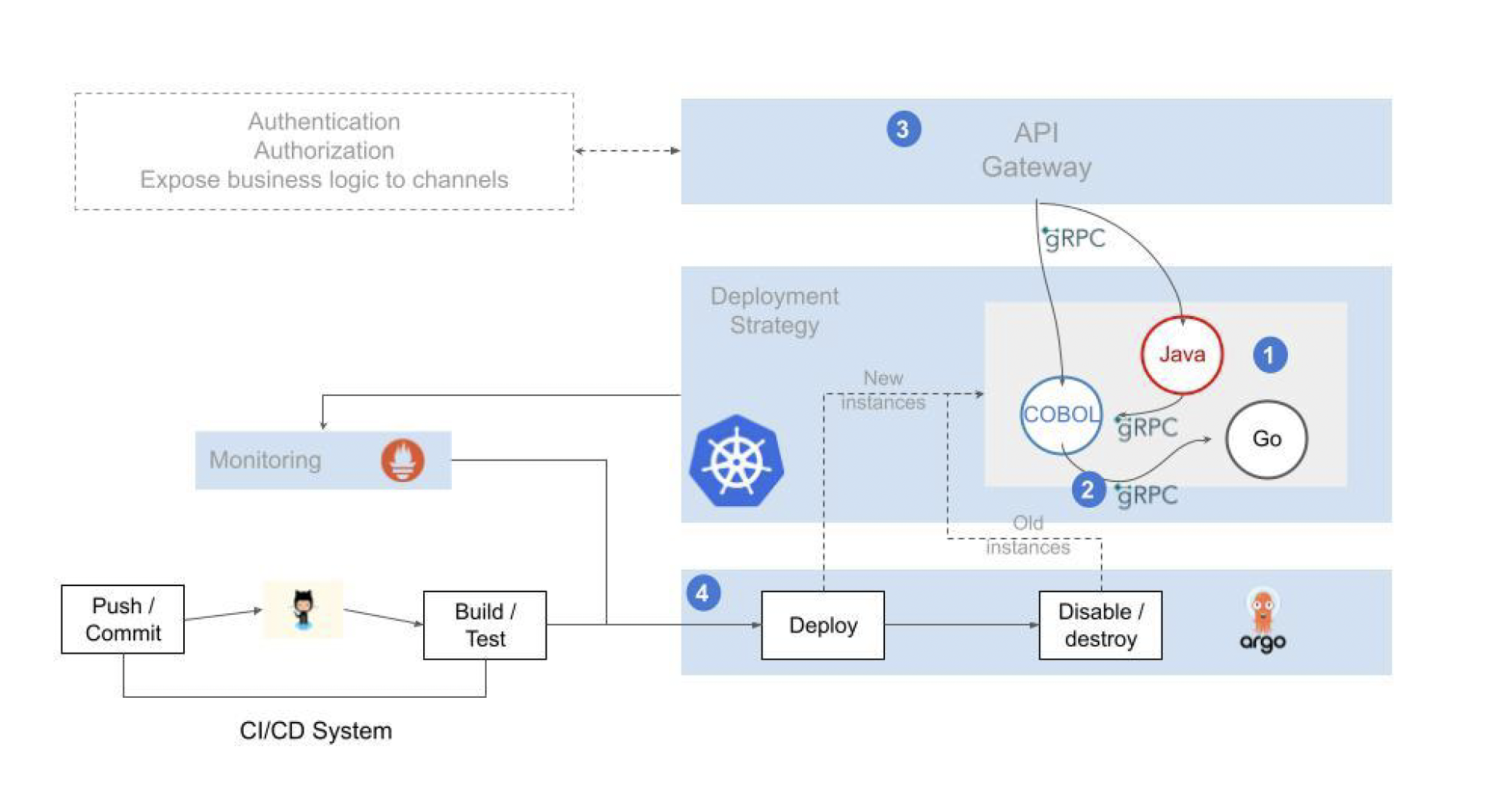
-
The solution allows services to be coded in modern languages that are attractive to developers. At the same time, it allows the use of programs coded in “legacy” languages, whose recoding would result in an unnecessary waste of resources.
-
Internal communication between the different services is implemented using a lightweight and efficient protocol.
-
Services are called from front-ends or third party systems through a secure, resilient and easily scalable exposing mechanism.
-
The operation is supported by automated deployment pipelines and advanced observability capabilities that provide an integrated and consistent view of the entire application flow and the health of the elements involved.
The remaining CICS statements common to application programs (ASKTIME/FORMATTIME, LINK, READQ TS, WRITEQ TS, RETURN, etc.) can be replaced directly by COBOL code (ASKTIME, RETURN, LINK) or by calling utilities developed in Go cgo.
DB2 statements
DB2 database access statements are of static type.
They must be precompiled. There are two ways to do this:
-
Use the pre-processor provided by the database vendor (e.g. Oracle Pro*COBOL).
-
Pre-process the DB2 statements (EXEC SQL) to use the SQL database access proxy provided by the coexistence architecture.
4.4 - Batch architecture
How do you run batch processes in an open architecture?
The following is a description of the main components of the IBM Batch architecture; it is important to understand the capabilities of each in order to replicate them on an open container-based architecture.
- JCL
- JES
- Application programs (COBOL, PL/I, etc.)
- Data (files and databases).
JCL
We can think of a JCL as a distant ancestor of a DAG (Directed Acrylic Graph), it is a set of sentences, inherited from punch card technology, that define the process and the sequence of steps to be executed.
In the JCL we find the basic characteristics of the process or job (name, type, priority, resources allocated, etc.), the sequence of programmes to be executed, the sources of input information and what to do with the output data of the process.
The main statements found in a JCL are the following
- A JOB card, where the name of the process and its characteristics are defined.
- One or more EXEC cards with each program to be executed.
- One or more DD cards defining the files (data sets) used by the previous programs.
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=PROGRAM1
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JES
The JES is the z/OS component (subsystem) responsible for batch processing. It performs two main tasks:
- Scheduling the batch processes
- Assigning the process to a class or initiator (jobs can be assigned to specific queues)
- Defining the priority of the process
- Allocating/limiting the resources assigned to the process (memory, time, etc.)
- Control the execution sequence (STEPs) of the process
- Execute programs
- Validate the JCL statements
- Loading programs (COBOL, PL/I) into memory for subsequent execution
- Assigning the input/output files to the symbolic names defined in the COBOL PL/I application programs
- Logging
Application programs
Programs, usually coded in COBOL, that implement the functionality of the process.
The executable program resulting from the compilation of the source code is stored as a member of a partitioned library (PDS). A specific card in the JCL (JOBLIB / STEPLIB) identifies the libraries from which the programs are to be loaded.
The JES calls the main program of the process (defined in the EXEC card of the JCL), which in turn can call various subroutines statically or dynamically.
Data
Data is accessed mainly through the use of files (datasets) and relational databases (DB2).
The input and output files are defined in the programs by means of a symbolic name.
SELECT LOAN ASSIGN TO "INPUT1"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
The assignment of symbolic names to read/write files is done in the JCL, via the DD card.
//*
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
The files are generally of one of the following types
- Sequential, the records must be accessed sequentially, i.e. to read the 1000th record, the previous 999 records must be read first.
- VSAM. There are different types of VSAM files, and it is possible to access the records directly using a key (KSDS) or a record number (RRDS).
In the case of access to a database (DB2), the information necessary for the connection (security, database name, etc.) is passed as parameters in the JCL.
Mainframe Batch Migration to Open Architecture
To migrate batch processes built on mainframe technology, we will replicate the functionality described above on a Kubernetes cluster.
It is therefore necessary to:
- Convert the JCLs (JOBs) to a tool or framework that allows the execution of workflows on a Kubernetes platform.
- Replicate the functionality of the JES to allow the scheduling and execution of COBOL PL/I programs on the Kubernetes cluster.
- Recompile the application programs.
- Provide access to data (files and databases).
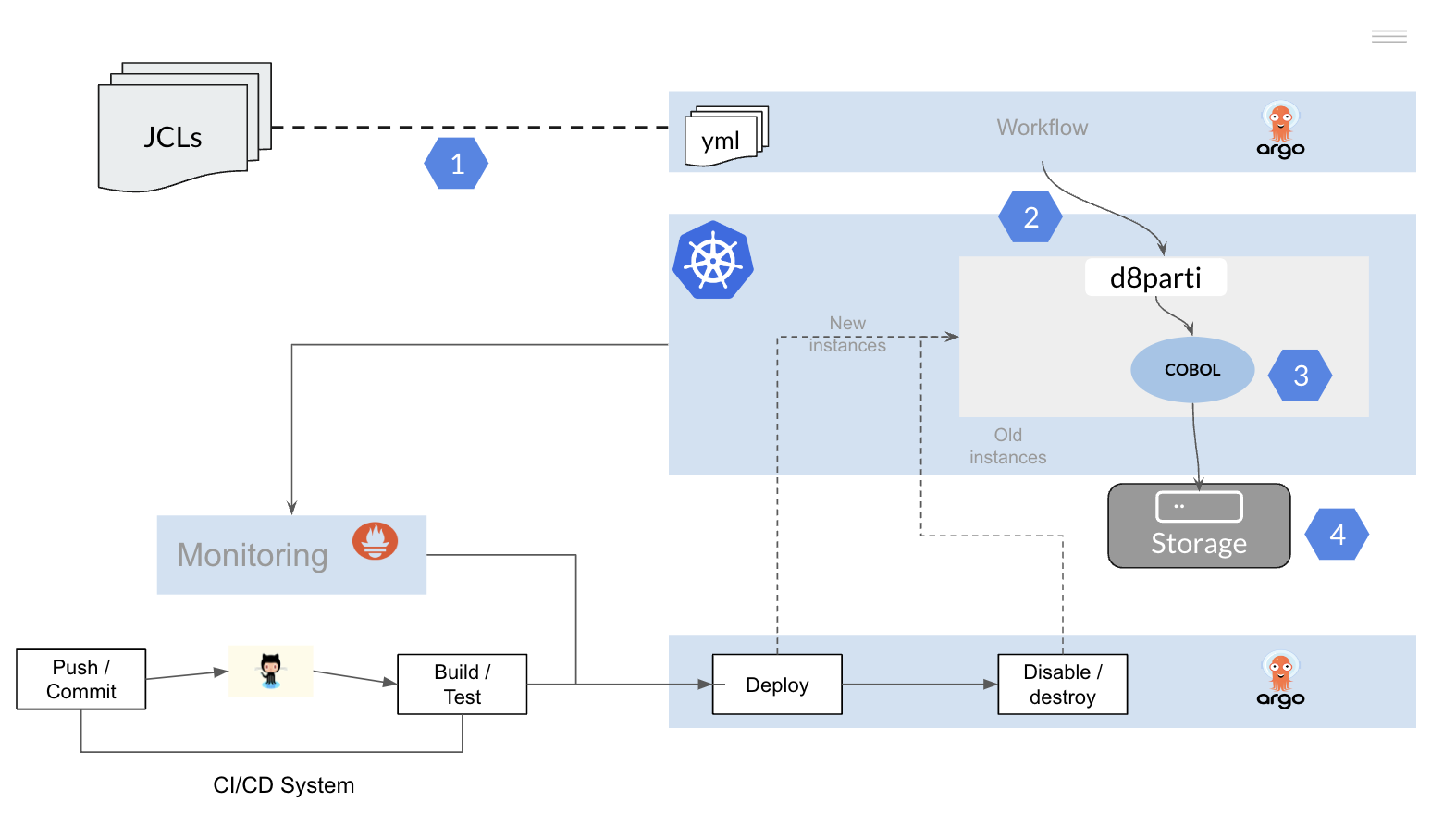
4.4.1 - Converting JCLs
How to convert a JCL mainframe into a DAG?
Below is a simple example of how to convert a JCL into an Argo workflow (yaml).
Other frameworks or tools that allow the definition of DAGs and have native integration with the Kubernetes platform can be used.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: batch-job-example
spec:
entrypoint: job
templates:
- name: job
dag:
tasks:
- name: extracting-data-from-table-a
template: extractor
arguments:
- name: extracting-data-from-table-b
template: extractor
arguments:
- name: extracting-data-from-table-c
template: extractor
arguments:
- name: program-transforming-table-c
dependencies: [extracting-data-from-table-c]
template: exec
arguments:
- name: program-aggregating-data
dependencies:
[
extracting-data-from-table-a,
extracting-data-from-table-b,
program-transforming-table-c,
]
template: exec
arguments:
- name: loading-data-into-table1
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: loading-data-into-table2
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: extractor
- name: exec
- name: loader
Batch ETL process divided into three phases:
- The extraction of information from a set of DB2 tables (template extractor).
- Transforming and aggregating these tables using COBOL applications (template exec).
- Loading the resulting information (template loader)
Each JOB is transformed into a DAG in which the sequence of tasks (STEPs) to be executed and their dependencies are defined.
Similarly to PROCS in the mainframe, it is possible to define templates with the main types of batch tasks of the installation (DB2 data download, execution of COBOL programs, file transfer, data conversion, etc.).
Each STEP within the DAG is executed in an independent container on a Kubernetes cluster.
Dependencies are defined at the task level in the DAG and non-linear execution trees can be built.
Result of the execution of the process, graphically displayed in Argo
4.4.2 - Replicate JES functionality
How to replicate how the JES works?
If you’re familiar with The Twelve-Factor App, you’ll know that one of its principles is to make the application code independent of any element that might vary when it’s deployed in different environments (test, quality, production, etc.).
Storing the configuration in the environment
An app’s config is everything that is likely to vary between deploys (staging, production, developer environments, etc)
We can translate the information contained in the JCLs into configuration files (config.yml), which contain the necessary information for running the code in each of the environments defined in the installation (resource allocation, connection to the database, name and location of the input and output files, level of detail of the logging, etc.).
To understand what functionality we need to replicate, let’s divide a JCL into two parts:
- JOB card
- EXEC and DD cards
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=BCUOTA
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JOB card
In the JOB card, we will find the basic information for scheduling the process in Kubernetes:
- Information needed to classify the JOB (CLASS). Allows you to classify the types of JOBs according to their characteristics and assign different execution parameters to them.
- Define default output (MSGCLASS).
- The level of information to be sent to the std out (MSGLEVEL)
- Maximum amount of memory allocated to the JOB (REGION)
- Maximum estimated time for execution of the process (TIME)
- User information (USER)
- Etc.
In Kubernetes, the kube-scheduler component is responsible for performing these tasks. It searches for a node with the right characteristics to run the newly created pods.
There are several options;
- Batch processes can use the Kubernetes job controller, it will run a pod for each task (STEP) of the workflow and stop it when the task is completed.
- If more advanced functionality is required, such as defining and prioritising different execution queues, specialised schedulers such as Volcano can be used.
- Finally, it is possible to develop a Kubernetes controller tailored to the specific needs of an installation.
EXEC & DD cards
In each STEP of the JCL we find an EXEC tab and several DD tabs.
It is in these cards that the (COBOL) program to be executed and the associated input and output files are defined. Below is an example of how to transform a STEP of JCL.
---
stepname: "step01"
exec:
pgm: "bcuota"
dd:
- name: "input1"
dsn: "dev/appl1/sample.txt"
disp: "shr"
normaldisp: "catlg"
abnormaldisp: "catlg"
- name: "output1"
dsn: "dev/appl1/cuota.txt"
disp: "new"
normaldisp: "catlg"
abnormaldisp: "delete"
For program execution, EXEC and DD instructions are converted to YAML. This information is passed to the d8parti controller, which specialises in running batch programs.
The d8parti controller acts like the JES:
- It is in charge of the syntax validation of the YAML file
- It maps the symbolic names in COBOL programs to physical input/output files
- Loads COBOL into memory for execution
- Writes monitoring/logging information
4.4.3 - Program compilation
How to reuse mainframe application programs?
The mainframe COBOL PL/I programs are directly reusable on the targeted technical platform (Linux).
As mentioned above, the d8parti module will be responsible for the following tasks
- Initialise the language runtime (i.e. COBOL)
- Assign the input/output files to the symbolic names of the program
- Loading and execution of the main program (defined in the EXEC tab of the JCL)
This main program can make various calls to other subroutines using a CALL statement. These calls are managed by the runtime of the language used.
We can visualise this operation as an inverted tree
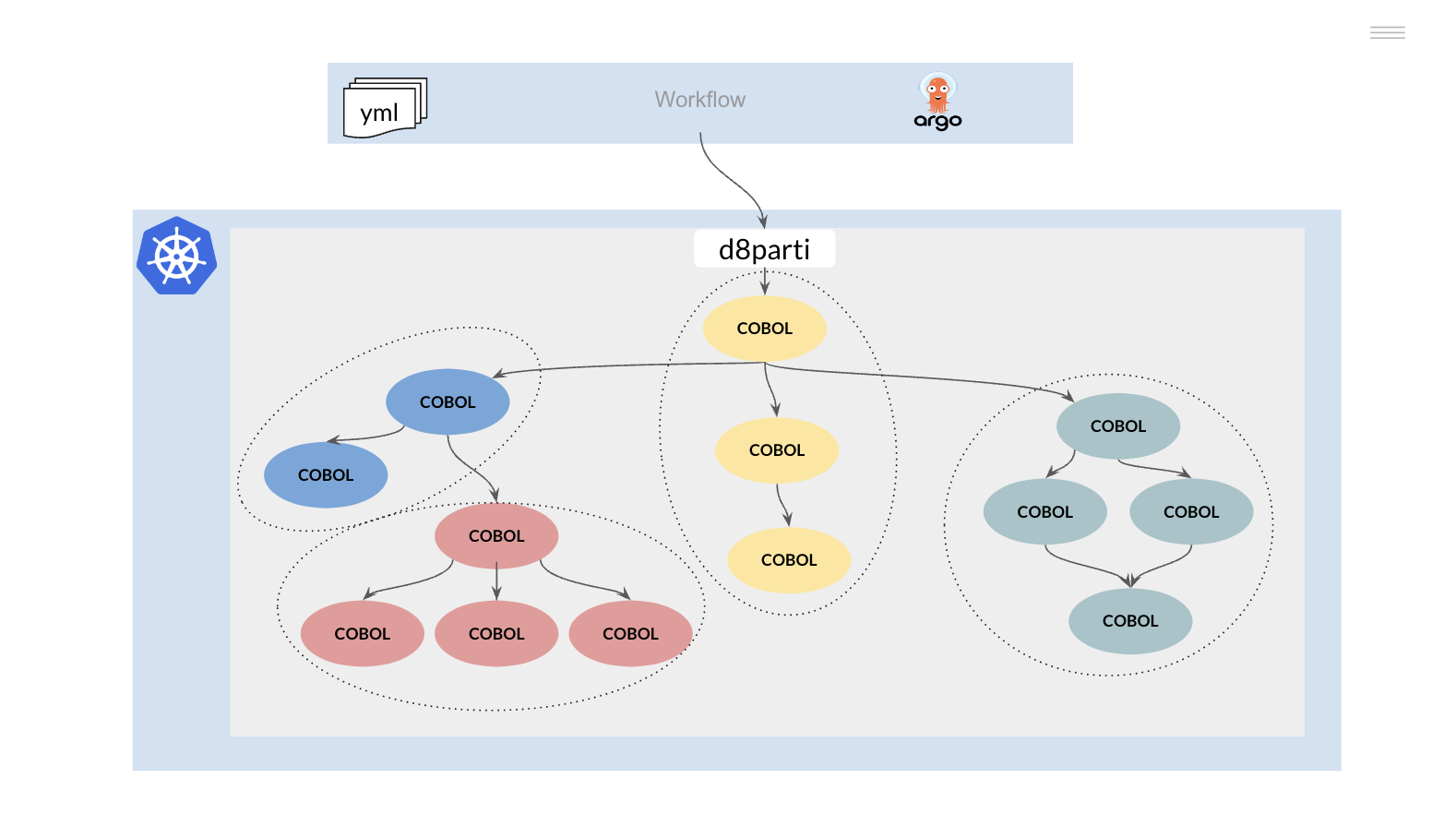
Compiled programs can be stored in a shared directory and loaded at runtime (dynamic CALL), mimicking the IBM mainframe (STEPLIB).
However, it is possible to change the above behaviour and implement an immutable container model, which has several advantages over the above model. In this case, the previous execution tree should be functionally decomposed into one or more repos.
Modifying any of the components of these repos generates a new version of the same and the corresponding regeneration of the container(s) that use it.
With this strategy we achieve
- Simplify the application development and testing process.
- Enable incremental introduction of changes to the system, minimizing risks
- Enable the portability of processes to different Cloud platforms (on-prem, on-cloud).
Once a business function has been isolated in a container with a standard interface, it can be modified or rewritten in any other programming language and deployed transparently without affecting the rest of the system.
4.4.4 - Data access
How to access data stored in SQL files and databases?
Files
In mainframe architecture, a Data Set is a set of related records stored in a UNIT / VOLUME.
To understand these concepts, we need to go back to the days when mass storage devices were based on tapes or cartridges. So when a process needed to access the information in a data set, the tape or cartridge had to be mounted in a UNIT and identified by a name or VOLUME.
Today, information resides on disk and does not need to be mounted/unmounted for access, we can compare mainframe VOLUMEs to an NFS share.
Different mount points can be defined for the application container to isolate the information and protect access (e.g. by environment, development and production). The containers are accessed via SDS (Software Define Storage) to decouple the storage from the process.
Finally, the mainframe files need to be transferred and converted (EBCDIC) into Linux files for use on the target platform. This process can be automated using off-the-shelf tools or using Spark data conversion processes.
SQL databases
The main mainframe database engine is IBM DB2, although other types of products (IMS DB, IDMS, Adabas) are still in use.
For DB2 applications, there are two main strategies for accessing data:
- Replication of DB2 data on a new SQL database (e.g. PostgreSQL).
- Accessing DB2 on the mainframe platform from the Kubernetes cluster using the Coexistence Proxy (DB2 Proxy).
In the first case, replication tools (e.g. IBM CDC) or ETL processes (e.g. using Spark) are used to replicate the data from the DB2 tables to a new SQL database.
The DB2 SQL statements (EXEC SQL … END-EXEC.) are pre-compiled to be able to access the new database manager, it is necessary to make small changes in the SQL to adapt it, but there is a methodology and tools to carry out this process automatically:
- DDL replication (tablespaces, tables, indexes, columns, etc.)
- Adapting the DATE/TIME data types.
- SQLCODEs
- Upload and download utilities
- Etc
The main drawback of this strategy is the need to maintain the data integrity of the model, generally the referential integrity model of the database is not defined in the DB2 manager, it must be deduced by the logic of the applications.
All read/update processes that access the affected tables (whether batch or online) must either be migrated to the new platform or a coexistence/replication mechanism must be defined between the platforms (mainframe DB2 / next-gen SQL). This mechanism must maintain data integrity on both platforms until the migration process is complete.
For tables containing master data accessed by a large number of applications, this coexistence is particularly critical.
There is no need to maintain data integrity between platforms (mainframe / next-gen) if you choose to continue accessing DB2 mainframe through the coexistence proxy. Processes (online or batch) can be migrated one at a time and in stages (canary deployment).
Once the process of migrating the application programs (Online and Batch) has been completed, the data can be migrated to a new database on the target platform (Next-gen).
5 - Tutorials
Tutorials
5.1 - COBOL variables
How to convert a COBOL COPYBOOK to a Go Struct?
Variables in the COBOL language.
Any COBOL program can be turned into a microservice and deployed in Kubernetes.
To do this, simply compile the program and generate an executable module that can be called dynamically or statically from another application program. You can refer to the examples to learn how to make both dynamic and static calls.
Similar to the functionality of a function in a contemporary programming language, these programs, or subroutines, can accept a set of variables as input parameters. The process is straightforward: the USING clause in the PROCEDURE DIVISION must be coded to replicate the number, sequence, and type of variables used in the call from the main program.
In the case of batch programs, the main program (associated with a STEP tab of a JCL) does not normally use parameters (PARM) to receive input variables to the program. Instead, programs often employ the COBOL ACCEPT statement or read the required information directly from a file.
In the case of online programs, the main program is associated with a transaction and the transaction manager (CICS or IMS) is responsible for calling this program. This program typically utilises the designated transaction manager sentences to receive a message comprising multiple variables (EXEC CICS RECEIVE - GN) within a pre-defined memory area.
Whatever the execution mode (online or batch), these main COBOL programs can in turn make multiple calls to COBOL subroutines using the CALL statement (in the case of CICS, this call could be made using the EXEC CICS LINK sentence).
Therefore, if we want to expose a COBOL program as a microservice that can be called by other microservices written in different programming languages, it is necessary to understand the different data types that a COBOL program can use and convert them to a standard type that can be used by any programming language.
Data types in COBOL
Defining a variable in a COBOL program can be confusing to someone used to working with modern programming languages. In addition, there are several data types that are commonly used by a COBOL programmer that have no equivalent in any modern programming language.
Let’s try to decipher the operation of the most commonly used COBOL data types in a standard program and define their translation to a modern language such as Go.
Variables that require double-byte characters are excluded.
As in any other language, to define a variable we must declare its name and type (string, int, float, bytes, etc.), however, in COBOL this definition is not done directly, it is done through the USAGE and PICTURE clauses.
01 VAR1 PIC S9(3)V9(2) COMP VALUE ZEROS.
The USAGE clause defines the internal memory storage to be used by the variable.
The PICTURE (or PIC) clause defines the mask associated with the variable and its general characteristics; this definition is done by using a set of specific characters or symbols:
- A, the variable contains alphabetic characters.
- X, the variable contains alphanumeric characters
- 9, numeric variable
- S, indicates a signed numeric variable
- V, number of decimal places
- Etc.
USAGE DISPLAY
Variables defined as USAGE DISPLAY can be of the following types
Alphabetical
They are defined by using the symbol A in the PICTURE clause.
01 VAR-ALPHA PIC A(20).
They can only store characters from the Latin alphabet. Their use is not very common, as they are generally replaced by alphanumeric variables, which we will see below.
Alphanumeric
They are defined by using the symbol X in the PICTURE clause.
01 VAR-CHAR PIC X(20).
As in the previous case, it is not necessary to define the USAGE clause, since variables of type A or X are of type DISPLAY by default.
Numeric
They are defined by using the symbol 9 in the PICTURE clause.
01 VAR1 PIC S9(3)V9(2) USAGE DISPLAY.
In this case, we define a numeric variable of length 5 (3 integer places and 2 decimal places) with sign.
The definition of numeric variables of type DISPLAY can be explicit, as in the previous example, or implicit if the USAGE clause is not declared.
Internal storage
Each of the defined characters is stored in a byte (EBCDIC), in the case of signed numeric type variables, the sign is defined in the first 4 bits of the last byte.
Let’s look at an example to better understand how this type of variable works.
| Number | EBCDIC value |
|---|---|
| 0 | x’F0' |
| 1 | x’F1' |
| 2 | x’F2' |
| 3 | x’F3' |
| 4 | x’F4' |
| 5 | x’F5' |
| 6 | x’F6' |
| 7 | x’F7' |
| 8 | x’F8' |
| 9 | x’F9' |
If we assign a value of 12345 to a variable of type
PIC 9(5) USAGE DISPLAY
It would take 5 bytes
12345 = x’F1F2F3F4F5’
In case of signed variables
PIC S9(5) USAGE DISPLAY
+12345 = x’F1F2F3F4C5’
-12345 = x’F1F2F3F4D5’
USAGE COMP-1 or COMPUTATIONAL-1
32-bit (4 bytes) float variable.
USAGE COMP-2 or COMPUTATIONAL-2
64-bit (8 bytes) float variable.
It is not possible to define a PICTURE clause associated with a COMP-1 or COMP-2 type variable.
USAGE COMP-3 or COMPUTATIONAL-3
Packed-Decimal variable.
01 VAR-PACKED PIC S9(3)V9(2) USAGE COMP-3.
4 bits are used to store each of the numeric characters of the variable, the sign is stored in the last 4 bits.
Generally, such variables are defined with an odd length to fill the total number of bytes used.
A simple rule to calculate the memory used by a COMP-3 type variable is to divide the total length of the variable (integer positions + decimal positions) by 2 and add 1, in the above example the memory required for the variable VAR-PACKED is;
5 / 2 = 2 -> Total length 5 (3 integers + 2 decimals)
2 + 1 = 3 -> storage requirement of 3 bytes
Let’s look at an example to better understand how this type of variable works.
Let’s assign the value 12345 to a variable of type COMP-3, as in the previous example.
PIC S9(5) USE COMP-3.
We start with the DISPLAY format number
x’F1F2F3F4F5'.
We remove the first 4 bits of each byte and add the sign at the end.
+12345 = x’12345C’
-12345 = x’12345D’
USAGE COMP-4 or COMPUTATIONAL-4 or COMP or BINARY
In this case the data type is binary. Negative numbers are represented as two’s complement.
The size of storage required depends on the PICTURE clause.
| PICTURE | Storage | Value |
|---|---|---|
| PIC S9(1) - S9(4) | 2 bytes | -32,768 to +32,767 |
| PIC S9(5) - S9(9) | 4 bytes | -2,147,483,648 to +2,147,483,647 |
| PIC S9(10) - S9(18) | 8 bytes | -9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 |
| PIC 9(1) - 9(4) | 2 bytes | 0 to 65,535 |
| PIC 9(5) - 9(9) | 4 bytes | 0 to 4,294,967,295 |
| PIC 9(10) - 9(18) | 8 bytes | 0 to 18,446,744,073,709,551,615 |
Up to this point, the operation of this type of variable would be equivalent to the representation of integer variables in most programming languages (short, long or double variables and their unsigned equivalents ushort, ulong, udouble), but by using the PICTURE clause we can limit the maximum values of such a variable and define a decimal mask.
For example:
01 VAR-COMP PIC 9(4)V9(2) USAGE COMP.
It uses 4 bytes of memory (int32), but its value is limited from 0 to 9999.99.
What is the point of defining integer variables and then defining a fixed mask with the number of integer and decimal places?
To restrict the use of floating point operations. This may seem strange today, but 30 years ago it made sense to reduce the number of CPU cycles used when the cost of computing was extremely high.
On the other hand, almost all operations performed by financial institutions with currencies do not require complex calculations, and by operating with integers we do not lose precision when we need decimals (i.e. cents).
USAGE COMP-5 or COMPUTATIONAL-5
This data type is also known as native binary.
It is equivalent to COMP-4, however the values to be stored are not limited by the mask defined in the PICTURE clause.
| PICTURE | Variable |
|---|---|
| PIC S9(4) COMP-5 | short (int16) |
| PIC S9(9) COMP-5 | long (int32) |
| PIC S9(18) COMP-5 | double (int64) |
| PIC 9(4) COMP-5 | ushort (uint16) |
| PIC 9(9) COMP-5 | ulong (uint32) |
| PIC 9(18) COMP-5 | udouble (uint64) |
Converting variables to a standard type
It is important to note that it is only necessary to convert the variables exposed by the main programs, once the COBOL runtime has initialised and executed the main program, the calls between COBOL programs made by means of the CALL statement are under the responsibility of the runtime.
A special case is the call between COBOL programs deployed in different containers. A special mechanism has been designed for this, similar to the operation of the LINK statement of the CICS transaction manager.
How to make calls between COBOL programs deployed in different application containers can be found in the examples section d8link.
In general, any COBOL variable could be exposed in different forms (int, float, string, etc.) and then converted, but to simplify and optimise the conversion process, we will use a set of simple rules that we will describe below.
EBCDIC
As mentioned above, the IBM mainframe uses EBCDIC internally.
In an attempt to replicate as closely as possible the behaviour of COBOL programs across platforms, some vendors allow EBCDIC to continue to be used internally for application data handling.
While this strategy may facilitate code migration in the short term, it presents huge compatibility, evolution and support problems in the medium to long term. Therefore, migrated COBOL programs will use ASCII characters internally.
It is necessary to identify programs that use COBOL statements that handle hexadecimal characters and replace these strings.
MOVE X’F1F2F3F4F5’ TO VAR-NUM1.
Big-endian vs. little-endian
The IBM mainframe platform is big-endian, so the most significant byte would be stored in the memory address with the smallest value, or in other words, the sign would be stored in the first bit from the left.
In contrast, the x86 and arm platforms use little-endian to represent binary variables.
As in the previous case, we believe that the best strategy is to use the target architecture natively, so the programs are compiled to use little-endian.
Maximum size of COMP variables
In general, the maximum size of a numeric variable is 18 digits, regardless of the type used (DISPLAY, COMP, COMP-3, COMP-5).
However, on the mainframe platform, it is possible to extend this limit to 31 digits for some types of variables (e.g. COMP-3).
We are talking about numeric variables that are used to carry out arithmetic operations, except in the specific case of a country with hyperinflationary episodes that have persisted over a long period of time, the limit of 18 digits is enough.
Binary Variables
Although it is not common to use binary variables with a decimal mask (COMP or COMP-4), they can be used to operate on large numbers using binary instructions, thus avoiding the use of floating point numbers.
In the case of COMP-5 or native binary variables, it does not make sense to use a decimal mask, so they are implemented directly into an integer variable type corresponding to their size.
Data types
| COBOL type | Go type |
|---|---|
| PIC X(n) | string |
| COMP-1 | float32 |
| COMP-2 | float64 |
| PIC S9(1 to 4) COMP-5 | int16 |
| PIC S9(5 to 9) COMP-5 | int32 |
| PIC S9(10 to 18) COMP-5 | int64 |
| PIC 9(1 to 4) COMP-5 | uint16 |
| PIC 9(5 to 9) COMP-5 | uint32 |
| PIC 9(10 to 18) COMP-5 | uint64 |
There is no string concept in COBOL. The size of the variable
PIC X(n)is exactly the length defined in thePICclause.If the size of the string is smaller than the size defined in COBOL, it must be justified with spaces on the right.
Now that we have defined the variables that are equivalent to a certain type of variable in the Go language, we will define the behaviour of the numeric data types with decimal mask.
These are the data types commonly used by COBOL programmers. In the event that the program is to be exposed for invocation from an external platform, variables of type DISPLAY or decimal zoned are usually used to facilitate data conversion (ASCII-EBCDIC) between platforms and to facilitate error debugging.
In our case, to simplify data handling, all these variables are exposed as string type.
| COBOL type | Go type |
|---|---|
| PIC S9(n) | string |
| PIC S9(n) COMP-3 | string |
| PIC S9(n) COMP or COMP-4 or BINARY | string |
The calling program must ensure that the data sent corresponds to a numerical value.
The variables received must conform to the mask defined in the
PICclause, while respecting the number of integer and decimal places and, if necessary, justifying with leading zeros.
The process of conversion
Let’s start with a simple example, a COBOL program that receives a data structure with different types of variables.
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. vars.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare variables in the WORKING-STORAGE section
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 MY-RECORD.
10 CHAR PIC X(09) VALUE SPACES.
10 COMP2 COMP-2 VALUE ZEROES.
10 COMP1 COMP-1 VALUE ZEROES.
10 COMP5D PIC S9(18) COMP-5 VALUE ZEROES.
10 COMP5L PIC S9(9) COMP-5 VALUE ZEROES.
10 COMP5S PIC S9(4) COMP-5 VALUE ZEROES.
10 COMP5UD PIC 9(18) COMP-5 VALUE ZEROES.
10 COMP5UL PIC 9(9) COMP-5 VALUE ZEROES.
10 COMP5US PIC 9(4) COMP-5 VALUE ZEROES.
10 NDISPLAY PIC S9(3)V9(2) VALUE ZEROES.
10 COMP3 PIC S9(3)V9(2) COMP-3 VALUE ZEROES.
10 COMP4D PIC S9(8)V9(2) COMP VALUE ZEROES.
10 COMP4L PIC S9(3)V9(2) COMP VALUE ZEROES.
10 COMP4S PIC S9(2)V9(2) COMP VALUE ZEROES.
PROCEDURE DIVISION USING BY REFERENCE MY-RECORD.
* code goes here!
DISPLAY "char: " CHAR.
DISPLAY "comp-2: " COMP2.
DISPLAY "comp-1: " COMP1.
DISPLAY "comp5 double: " COMP5D.
DISPLAY "comp5 long: " COMP5L.
DISPLAY "comp5 short: " COMP5S.
DISPLAY "comp5 Udouble: " COMP5UD.
DISPLAY "comp5 Ulong: " COMP5UL.
DISPLAY "comp5 Ushort: " COMP5US.
DISPLAY "display: " NDISPLAY.
DISPLAY "comp-3: " COMP3.
DISPLAY "comp double: " COMP4D.
DISPLAY "comp long: " COMP4L.
DISPLAY "comp short: " COMP4S.
MOVE 0 TO RETURN-CODE.
GOBACK.
Then we will analyse this structure (it can be parsed automatically) and generate two files:
A configuration file (vars.yml) with the characteristics of the COBOL variables present in the structure to be converted (name, type of variable, length, decimal places, sign).
type = 0 -> numeric, type
DISPLAYtype = 1 -> numeric, type
COMP-1type = 2 -> numeric, type
COMP-2type = 3 -> numeric, type
COMP-3type = 4 -> numeric, type
COMP-4 or BINARY or COMPtype = 5 -> numeric, type
COMP-5type = 9 -> alphanumeric, type
CHAR
---
copy:
- field: "Char"
type: 9
length: 9
decimal: 0
sign: false
- field: "Comp2"
type: 2
length: 0
decimal: 0
sign: true
- field: "Comp1"
type: 1
length: 0
decimal: 0
sign: true
- field: "Comp5Double"
type: 5
length: 18
decimal: 0
sign: true
- field: "Comp5Long"
type: 5
length: 9
decimal: 0
sign: true
- field: "Comp5Short"
type: 5
length: 4
decimal: 0
sign: true
- field: "Comp5Udouble"
type: 5
length: 18
decimal: 0
sign: false
- field: "Comp5Ulong"
type: 5
length: 9
decimal: 0
sign: false
- field: "Comp5Ushort"
type: 5
length: 4
decimal: 0
sign: false
- field: "NumDisplay"
type: 0
length: 5
decimal: 2
sign: true
- field: "Comp3"
type: 3
length: 5
decimal: 2
sign: true
- field: "CompDouble"
type: 4
length: 10
decimal: 2
sign: true
- field: "CompLong"
type: 4
length: 5
decimal: 2
sign: true
- field: "CompShort"
type: 4
length: 4
decimal: 2
sign: true
A file (request.go) containing the Go representation of the COBOL structure.
package request
type Request struct {
Char string
Comp2 float64
Comp1 float32
Comp5Double int64
Comp5Long int32
Comp5Short int16
Comp5Udouble uint64
Comp5Ulong uint32
Comp5Ushort uint16
NumDisplay string
Comp3 string
CompDouble string
CompLong string
CompShort string
}
And finally, a file (response.go). The structure used above can be copied as the parameters used by the program are input/output.
package response
type Response struct {
Char string
Comp2 float64
Comp1 float32
Comp5Double int64
Comp5Long int32
Comp5Short int16
Comp5Udouble uint64
Comp5Ulong uint32
Comp5Ushort uint16
NumDisplay string
Comp3 string
CompDouble string
CompLong string
CompShort string
}
Now we have everything we need to run our COBOL program.
Running the test program
The following explains how to run the above test program.
The examples can be downloaded directly from the GitHub repo.
The directory structure of the example (d8vars) is as follows:
├── cmd
├── cobol
├── conf
├── internal
│ └── cgocobol
│ └── common
│ └── service
├── model
│ └── request
│ └── response
├── test
│ go.mod
│ go.sum
| Dockerfile
/cobol
Contains the compiled COBOL programs to be executed (*.dylib or *.so).
Use the following compilation options to define the required behaviour for binary type fields.
cobc -m vars.cbl -fbinary-byteorder=native -fbinary-size=2-4-8
/conf
Configuration files described above, used to describe the COBOL COPY structure.
/model.
Contains the definition of the data structures in Go (request/response).
/internal.
In this case we find a simplified version of the code needed to convert data between languages and to execute the COBOL programs.
/test.
Finally, the test directory contains a utility for generating random test data according to the data types defined in the COBOL program.
To run the code, simply go to the /cmd directory, open a terminal and type
go run .
Remember to define to the COBOL language runtime the directory where the modules to be executed are located.
export COB_LIBRARY_PATH=/my_dir/.../cobol
The program will generate a random data structure, convert it to a format that can be used by the COBOL program, execute the program and convert the result to a format that can be used by the Go program.
You may wish to use the example COBOL program loancalc.cbl for further testing purposes. To do so, simply compile the program and modify the configuration and data structure files.
Please modify the app.env file to define the name of the COBOL program to be executed and the name of the COBOL copy to be converted.
COBOL_PROGRAM="loancalc"
COBOL_CONFIG="loancalc.yaml"
Copy the file loancalc.yml to the folder conf
---
copy:
- field: "PrincipalAmount"
type: 0
length: 7
decimal: 0
sign: true
- field: "InterestRate"
type: 0
length: 4
decimal: 2
sign: true
- field: "TimeYears"
type: 0
length: 2
decimal: 0
sign: true
- field: "Payment"
type: 0
length: 9
decimal: 2
sign: true
- field: "ErrorMsg"
type: 9
length: 20
decimal: 0
sign: false
And replace the request.go and response.go structures with the following:
package request
type Request struct {
PrincipalAmount string
InterestRate string
TimeYears string
}
package response
type Response struct {
Payment string
ErrorMsg string
}