Conceptos básicos
Cómo desmontar un mainframe IBM … y no morir en el intento
Un servidor IBM mainframe está diseñado como una arquitectura monolítica altamente acoplada. Los programas de aplicación se comunican entre ellos y con los repositorios de datos mediante el intercambio de direcciones de memoria (punteros).
¿Cómo es posible desmontar este monolito de manera progresiva y segura para minimizar los riesgos del proceso?
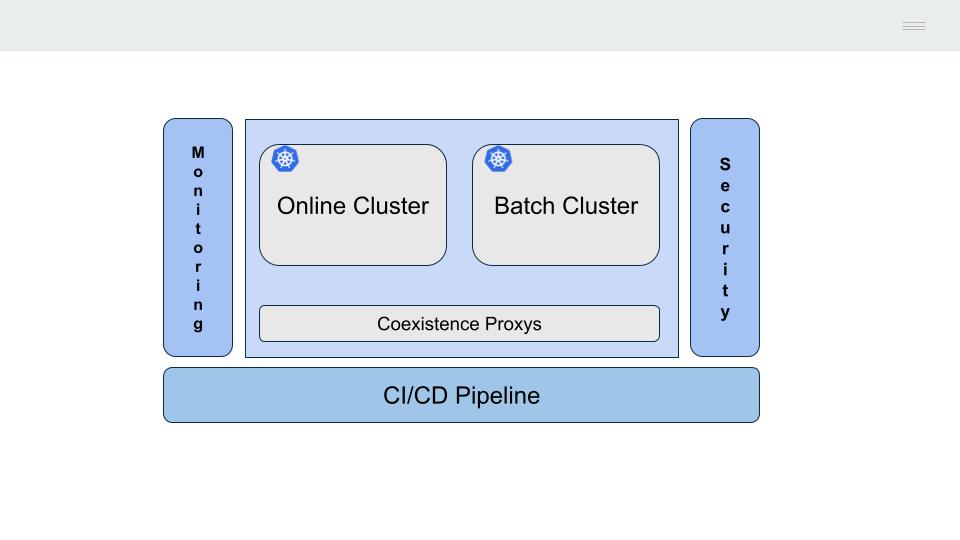
1 - Strangler Fig Pattern
¿Cómo desmontar una arquitectura monolítica de manera segura?
El servidor IBM mainframe es un sistema monolítico, no existe una separación clara entre los distintos niveles o capas de la arquitectura técnica, todos los procesos residen en la misma máquina (CICS, Batch, Base de Datos, etc).
La comunicación entre los distintos procesos (llamadas entre programas, acceso a la base de datos DB2, etc) se realiza mediante el uso de memoria compartida, este mecanismo presenta la ventaja de ser muy eficiente (necesaria el siglo pasado cuando los costes de computación eran muy elevados) con la contrapartida de acoplar fuertemente los procesos haciendo muy difícil su actualización o sustitución.
Esta última característica hace que la alternativa más viable para la migración progresiva de la funcionalidad desplegada en el Mainframe sea adoptar el modelo descrito por Matin Fowler como Strangler Fig.
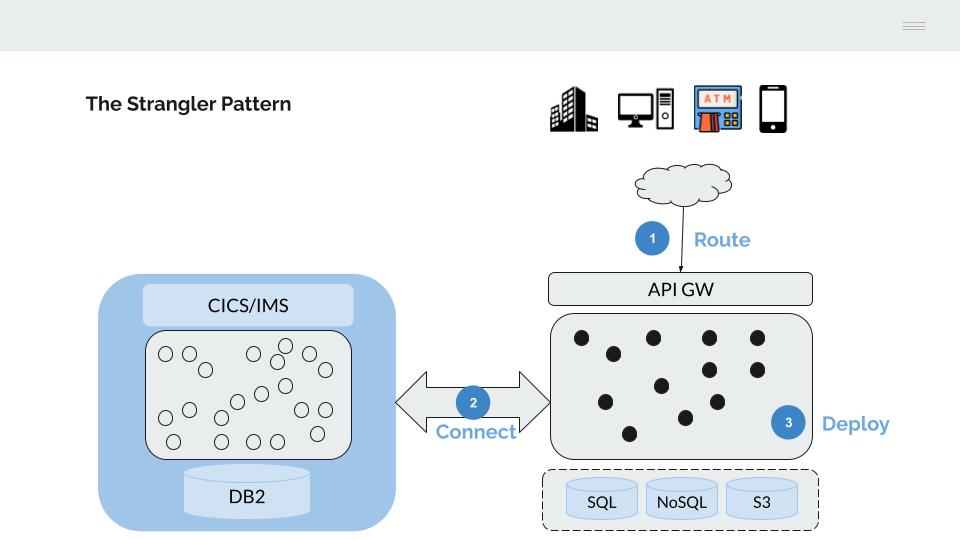
- El tráfico desde los canales, se mueve progresivamente hacia un API Gateway, que servirá para enrutar este hacia las plataformas de back-end (Mainframe o Next-gen)
- Se conectan ambas plataformas para permitir la realización de un despliegue de aplicaciones faseado
- Se migran progresivamente las aplicaciones hasta vaciar de contenido el servidor IBM mainframe
API Gateway
La conexión desde los canales se deriva de manera progresiva hacia un API Gateway.
Este API Gateway cumple dos funciones principales:
-
Por un lado, podemos entender este API Gateway como el sustituto de la funcionalidad proporcionada por el Monitor Transaccional CICS, gestionando;
- La comunicación (envío/recepción) con los canales, vamos a sustituir los códigos de transacción de 4 caracteres del CICS por APIs bien formadas
- El proceso de identificación (authentication), sustitución de CESN/CESF y RACF por un mecanismo basado en LDAP
- La autorización de operaciones, sustitución del RACF por un mecanismo basado en ACLs/RBAC
-
Por otro lado, este API Gateway nos servirá para dirigir (“Route”) el tráfico desde los canales hacia la plataforma destino, sustituyendo de manera progresiva la funcionalidad del servidor IBM mainframe por funcionalidad equivalente en la plataforma Next-gen.
Para permitir el despliegue progesivo de funcionalidad es necesario conectar ambas plataformas, estos mecanismos de conexión son esenciales para evitar la realización de despliegues “big-bang”, facilitar la marcha atrás en caso de problemas, permitir la realización de paralelos, etc, en definitiva, minimizar los riesgos inherentes a un proceso de cambio como el planteado.
Existen dos mecanismos básicos de conexión;
Proxy acceso DB2
El z/DB2 ofrece varios mecanismos de acceso mediante drivers jdbc y odbc.
De manera equivalente a la funcionalidad proporcionada por el CICS en su conexión al DB2, el proxy DB2 gestiona un pool de conexiones a la base de datos, el proceso de identificación/autorización y el cifrado del tráfico.
Proxy CICS/IMS
Permite la ejecución de transacciones mediante una conexión de bajo nivel basada en TCP/IP Sockets.
Despliegue de funcionalidad
Existen tres alternativas para la migración de la funcionalidad mainframe hacia una arquitectura Cloud.
Rebuild
La funcionalidad puede rediseñarse, escribirse en un lenguaje de programación moderno (java, python, go, …) y desplegarse como un microservicio en la plataforma Next-gen.
Estos nuevos programas pueden reutilizar la plataforma mainframe mediante la arquitectura de convivencia descrita anteriormente.
- Ejecución de sentencias SQL de acceso al DB2 a través del proxy DB2
- Invocación de una transacción mainframe mediante la llamada al proxy CICS/IMS
Refactor
En este caso, compilamos el código COBOL mainframe sobre la plataforma Next-gen (Linux-x86/arm) y lo desplegamos como un microservicio, de manera equivalente a un cualquier otro microservicio construido en java, python, go, etc.
Replace
Llamando a las APIs proporcionadas por un producto de terceros que implemente la funcionalidad requerida.
Las anteriores alternativas no son excluyentes, pueden seleccionarse diferentes alternativas para cada funcionalidad o aplicativo mainframe, sin embargo todas comparten la misma arquitectura técnica, el mismo pipeline para la construcción y despliegue y se benefician de las ventajas proporcionadas por la nueva plataforma técnica (seguridad, cifrado, automatización, etc.).
2 - Modelo de microservicios
¿Qué modelo de construcción de microservicios necesitamos para ejecutar programas COBOL?
El modelo de construcción de microservicios debe permitir:
- El uso de distintos lenguajes de programación (incluido COBOL)
- Que los microservicios sean interoperables (entre ellos y con la lógica del mainframe)
- La migración de datos entre plataformas (Mainframe DB2 / Next-gen SQL)
Para ello, vamos a utilizar como modelo de referencia la Hexagonal architecture.
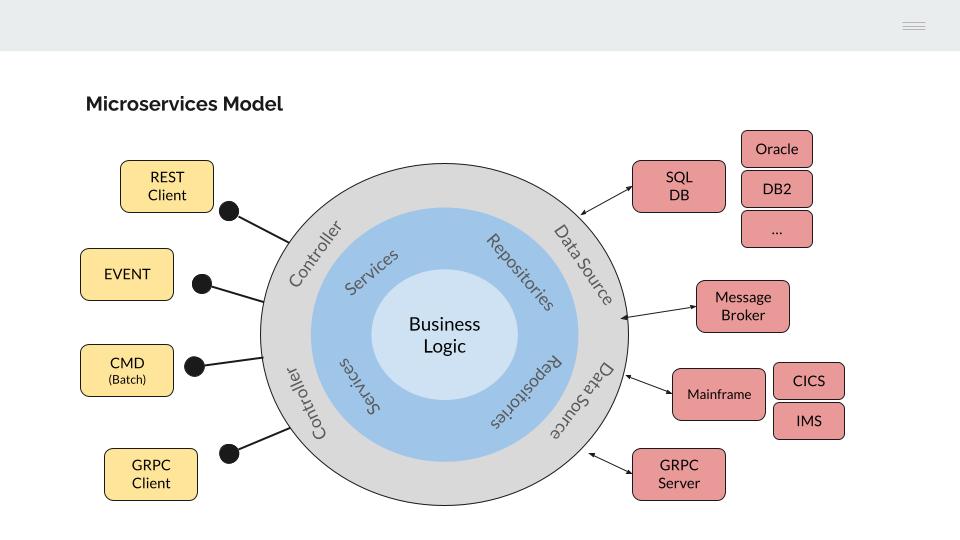
Si observamos la parte izquierda del modelo, los programas de aplicación están desacoplados de la interfaz utilizada para su ejecución. Este concepto nos debe resultar familiar ya que es equivalente al modelo utilizado en la construcción de aplicaciones COBOL en un mainframe IBM.
El lenguaje COBOL tiene sus orígenes en los años 60 del siglo pasado, cuando todo el procesamiento se realizaba en Batch. IBM desarrolla posteriormente sus monitores transaccionales CICS/IMS para permitir la conexión de los programas COBOL con dispositivos de su arquitectura de comunicaciones SNA.
Los programas COBOL manejan únicamente estructuras de datos (COBOL COPYBOOKS) y es el monitor transaccional el encargado de gestionar la interfaz de comunicación (LU0, LU2, Sockets, MQSeries, etc)
De manera equivalente, la funcionalidad de negocio implementada en los microservicios se independiza de la interfaz utilizada para su invocación, mediante un “controlador” específico.
Esto nos va a permitir la reutilización de la lógica aplicativa desde distintos interfaces, por ejemplo:
- API REST (json)
- API gRPC (proto)
- Eventos (kafka consumer)
- Consola (procesos Batch)
- Etc.
Los programas COBOL se adaptan a la perfección a este modelo, solo es necesario un proceso de conversión desde la interfaz seleccionada (json / proto) a una estructura COPYBOOK.
Atendiendo a la parte derecha del modelo, la lógica de negocio debería ser agnóstica de la infraestructura necesaria para la recuperación de los datos.
Si bien este modelo presenta evidentes ventajas, el nivel de abstracción y complejidad a introducir en el diseño y construcción de los microservicios es elevado, lo que nos lleva a hacer una implementación parcial del modelo, centrándonos en dos aspectos relevantes que aportan valor;
Bases de Datos SQL
El acceso al DB2 del mainframe se realiza a través de un proxy.
Este proxy expone una interfaz gRPC para permitir su invocación desde microservicios escritos en distintos lenguajes de programación.
Este mismo mecanismo se replica para el acceso a otros gestores de bases de datos SQL (por ejemplo, Oracle o PostgreSQL).
La migración de datos entre plataformas (por ejemplo de DB2 a Oracle) se facilita mediante la configuración en el microservicio del Data Source destino.
Invocación de transacciones CICS/IMS
En este caso, los programas CICS/IMS se exponen como microservicios (http/REST o gRPC), facilitando su posterior migración siempre que se respete la estructura de datos manejada por el programa.
3 - Arquitectura Online
¿Cómo migrar las transacciones CICS/IMS a microservicios?
La respuesta debería ser bastante sencilla, compilando el programa COBOL y desplegando el objeto en un contenedor (por ejemplo, Docker).
Sin embargo, existen dos tipos de sentencias en los programas Online que forman parte del lenguaje y que deben ser pre-procesadas previamente:
- Las sentencias del monitor transaccional utilizado (CICS/IMS)
- Las sentencias de acceso a la base de datos DB2
Sentencias CICS
Los programas Online se despliegan en un monitor transaccional (CICS/IMS), este realiza una serie de funciones que no pueden realizarse utilizando directamente el lenguaje de programación COBOL.
La principal función sería el envío/recepción de mensajes.
El lenguaje COBOL tiene sus orígenes a mediados del SXX, cuando todo el procesamiento se realizaba en batch, no existían dispositivos con los que conectarse
El monitor transaccional es por tanto el encargado de gestionar la comunicación. Los programas COBOL definen una estructura de datos fija (COPYBOOK) e incluyen como parte de su código sentencias CICS (EXEC CICS SEND/RECEIVE) para el envío o recepción de mensajes de aplicación.
El monitor transaccional utilizará la dirección (puntero) y longitud de la COPYBOOK para leer/escribir sobre ella el mensaje
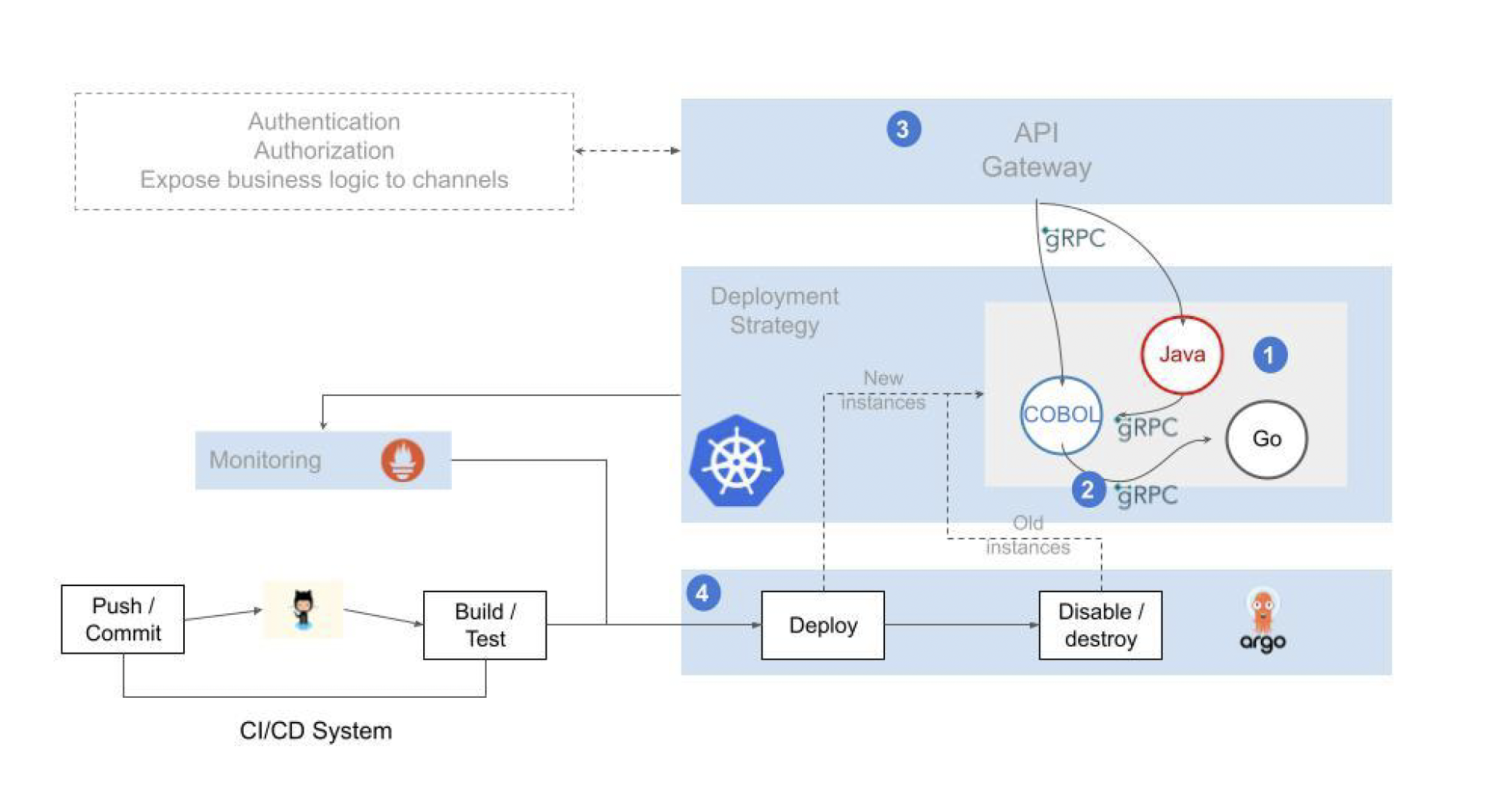
El modelo de microservicios propuesto se comporta de manera equivalente al CICS/IMS, extendiendo las capacidades del gRPC/proto al lenguaje COBOL.
-
Las COPYBOOK del programa COBOL (datos en LINKAGE SECTION) utilizadas para enviar/recibir mensajes se transforman en mensajes proto
-
Un controlador especializado se encarga de gestionar la interfaz gRPC (gRPC server)
-
El mensaje se convierte de formato proto a COPYBOOK. Se transforman los datos del mensaje (string, int, float, etc.) a datos COBOL (CHAR, DECIMAL, PACKED DECIMAL, etc.)
-
Finalmente se usa Go cgo para cargar el programa COBOL y ejecutarlo pasándole la estructura de datos generada
-
La solución permite la codificación de servicios en lenguajes modernos y atractivos para los desarrolladores. A su vez permite el aprovechamiento de piezas codificadas en lenguajes “legacy” cuya recodificación resultaría en un gasto de recursos innecesario
-
La comunicación entre los diferentes servicios, comunicación interna, se implementa mediante un protocolo ligero y eficiente
-
Los servicios son invocados desde frontales o sistemas de terceros (plataformas de pagos de terceros, software de partners u otras entidades, etc.) a través de un mecanismo de exposición securizado, resiliente y fácilmente escalable
-
La operación está soportada por pipelines para la automatización de los despliegues y capacidades avanzadas de observabilidad que permiten una visión integrada y consistente de todo el flujo aplicativo y del estado de salud de los elementos involucrados
El resto de sentencias CICS comunes en los programas de aplicación (ASKTIME/FORMATTIME, LINK, READQ TS, WRITEQ TS, RETURN, etc) pueden sustituirse directamente por código COBOL (ASKTIME, RETURN, LINK) o por llamadas a utilidades desarrolladas en Go cgo.
Sentencias DB2
Las sentencias de acceso a la base de datos DB2 son de tipo estático.
Estas deben pre-compilarse, existiendo dos opciones:
-
Utilizar el pre-procesador proporcionado por el fabricante de la base de datos (por ejemplo, Oracle Pro*COBOL)
-
Pre-procesar las sentencias DB2 (EXEC SQL) para utilizar el Proxy de acceso a base de datos SQL proporcionado por la arquitectura de convivencia
4 - Arquitectura Batch
¿Cómo ejecutar procesos Batch en una arquitectura open?
A continuación se describen los principales componentes de la arquitectura Batch de IBM, es importante entender las capacidades de cada uno de ellos para replicarlas sobre una arquitectura open basada en contenedores.
- JCL
- JES
- Programas de aplicación (COBOL, PL/I, etc.)
- Datos (Ficheros y Bases de Datos.)
JCL
Podemos pensar en un JCL como un antepasado lejano de un DAG (Directed Acrylic Graph), es un conjunto de sentencias, heredadas de la tecnología de las fichas perforadas, que definen el proceso y la secuencia de pasos a ejecutar.
En el JCL vamos a encontrar las características básicas del proceso o job (nombre, tipo, prioridad, recursos asignados, etc.), la secuencia de programas a ejecutar, las fuentes de información de entrada y qué hacer con los datos de salida del proceso.
Las principales sentencias que encontraremos en un JCL son las siguientes;
- Una ficha JOB, donde se define el nombre del proceso y sus características
- Una o varias fichas EXEC con cada programa que debe ser ejecutado
- Una o varias fichas DD, con la definición de los ficheros (Data Sets) utilizados por los programas anteriores
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=PROGRAM1
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JES
El JES es el componente (subsistema) del Z/OS que se encarga de procesar el Batch. Realiza dos tareas principales:
- La planificación (scheduling) de los procesos Batch
- Asignación del proceso a una clase o iniciador (los jobs pueden asignarse a colas específicas)
- Definir la prioridad del proceso
- Asignar/limitar los recursos asignados al proceso (memoria, tiempo, etc.)
- Controlar el flujo de ejecución de los pasos (STEPs) del proceso
- La ejecución de los programas
- Validación de las sentencias del JCL
- Cargar los programas (COBOL, PL/I) en memoria para su posterior ejecución
- Asignación de los ficheros de entrada/salida a los nombres simbólicos definidos en los programas de aplicación COBOL PL/I
- Logging
Programas de aplicación
Programas, generalmente codificados usando COBOL, que implementan la funcionalidad del proceso.
El ejecutable resultado de la compilación del código fuente se almacena como un miembro de una librería particionada (PDS). Las librerías desde donde cargar los programas se identifican mediante una ficha específica en el JCL (JOBLIB / STEPLIB).
El JES invocará al programa principal del proceso (definido en la ficha EXEC del JCL) y este a su vez podrá llamar a distintas subrutinas de manera estática o dinámica.
Datos
El acceso a los datos se realiza principalmente mediante la utilización de ficheros (Data Sets) y Bases de Datos relacionales (DB2).
Los ficheros de entrada/salida se definen en los programas con un nombre simbólico.
SELECT LOAN ASSIGN TO "INPUT1"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
La asignación de los nombres simbólicos a ficheros de lectura/escritura se realiza en el JCL, mediante la ficha DD.
//*
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
Los ficheros generalmente son de tipo;
- Secuencial, los registros deben ser accedidos de manera secuencial, es decir, para leer el registro 1.000 previamente han leerse los anteriores 999 registros
- VSAM. Existen distintos tipos de ficheros VSAM, siendo posible acceder a los registros directamente mediante mediante una clave (KSDS) o número de registro (RRDS)
En el caso de que el programa necesite acceder a una Base de Datos (DB2), la información necesaria para la conexión (seguridad, nombre de la Base de Datos, etc.) se pasa como parámetros en el JCL.
Migración del Batch mainframe a una arquitectura open
Para la migración de los procesos Batch construidos sobre tecnología mainframe vamos a replicar la funcionalidad descrita anteriormente sobre un clúster Kubernetes.
Es necesario por tanto;
- Convertir los JCLs (JOBs) a una herramienta o framework que permita la ejecución de workflows sobre una plataforma Kubernetes
- Replicar las funcionalidad del JES para permitir el scheduling y ejecución de los programas COBOL PL/I sobre el cluster Kubernetes
- Recompilar los programas de aplicación
- Permitir el acceso a los datos (ficheros y Bases de Datos)
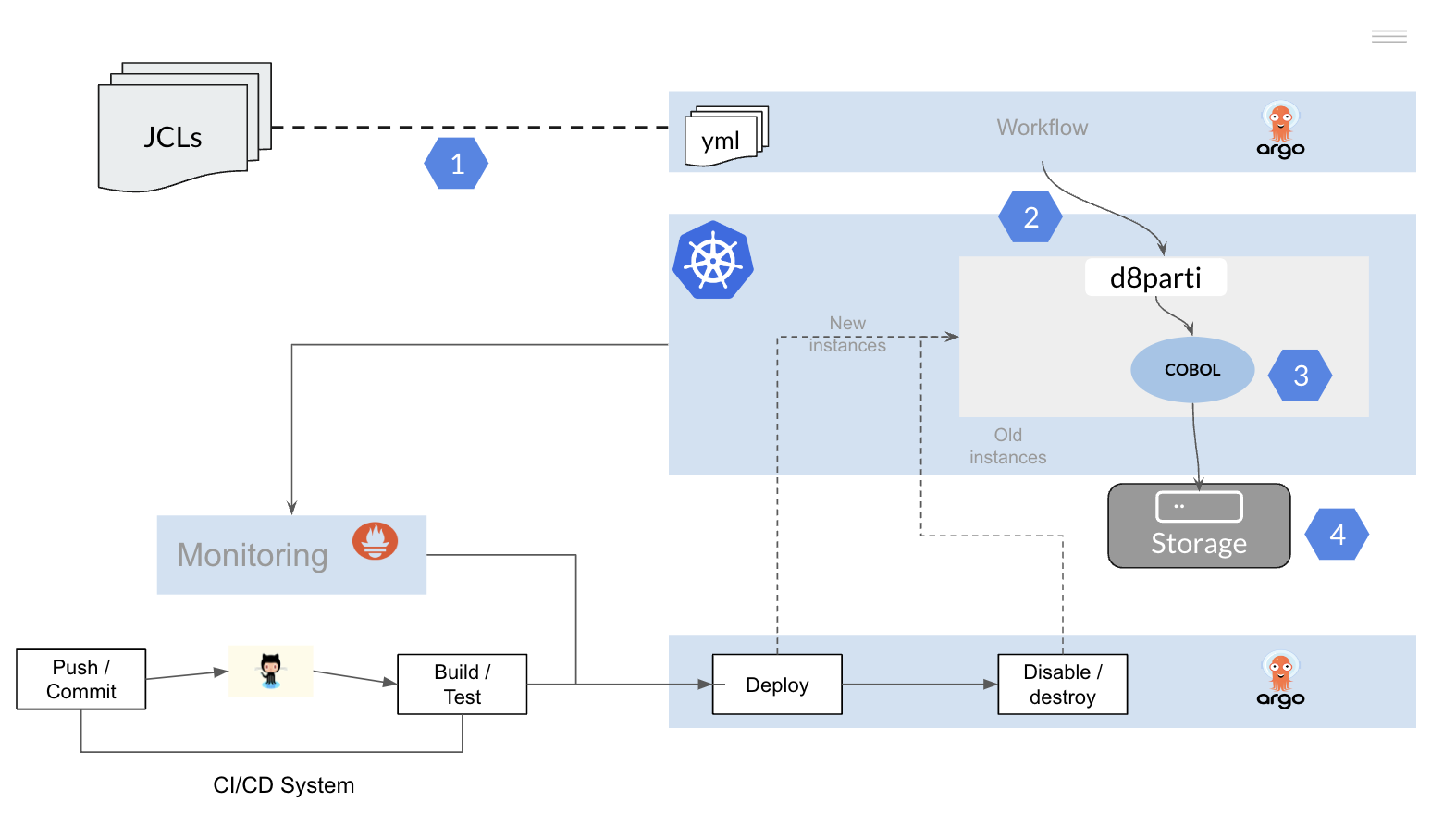
4.1 - Conversión JCLs
¿Cómo convertir un JCL mainframe en un DAG?
A continuación se muestra un sencillo ejemplo de cómo convertir un JCL a un workflow de Argo (yaml).
Pueden utilizarse otros frameworks o herramientas que permitan la definición de DAGs y tengan una integración nativa con la plataforma Kubernetes.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: batch-job-example
spec:
entrypoint: job
templates:
- name: job
dag:
tasks:
- name: extracting-data-from-table-a
template: extractor
arguments:
- name: extracting-data-from-table-b
template: extractor
arguments:
- name: extracting-data-from-table-c
template: extractor
arguments:
- name: program-transforming-table-c
dependencies: [extracting-data-from-table-c]
template: exec
arguments:
- name: program-aggregating-data
dependencies:
[
extracting-data-from-table-a,
extracting-data-from-table-b,
program-transforming-table-c,
]
template: exec
arguments:
- name: loading-data-into-table1
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: loading-data-into-table2
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: extractor
- name: exec
- name: loader
Proceso Batch de ETL dividido en tres fases:
- La extracción de información desde un conjunto de tablas DB2 (template extractor)
- La transformación y agregación de las mismas mediante programas de aplicación COBOL (template exec)
- La carga de la información resultante (template loader)
Cada JOB se transforma en un DAG en el que se define la secuencia de pasos (STEPs) a ejecutar y sus dependencias
Es posible definir “templates” con los principales tipos de tareas Batch de la instalación (descarga datos DB2, ejecución de programas COBOL, transmisión de ficheros, conversión de datos, etc.) de manera equivalente a los PROCS en mainframe
Cada STEP dentro del DAG es ejecutado en un contenedor independiente en un cluster Kubernetes
Las dependencias se definen a nivel de tarea en el DAG, pudiendo establecer árboles de ejecución no lineales
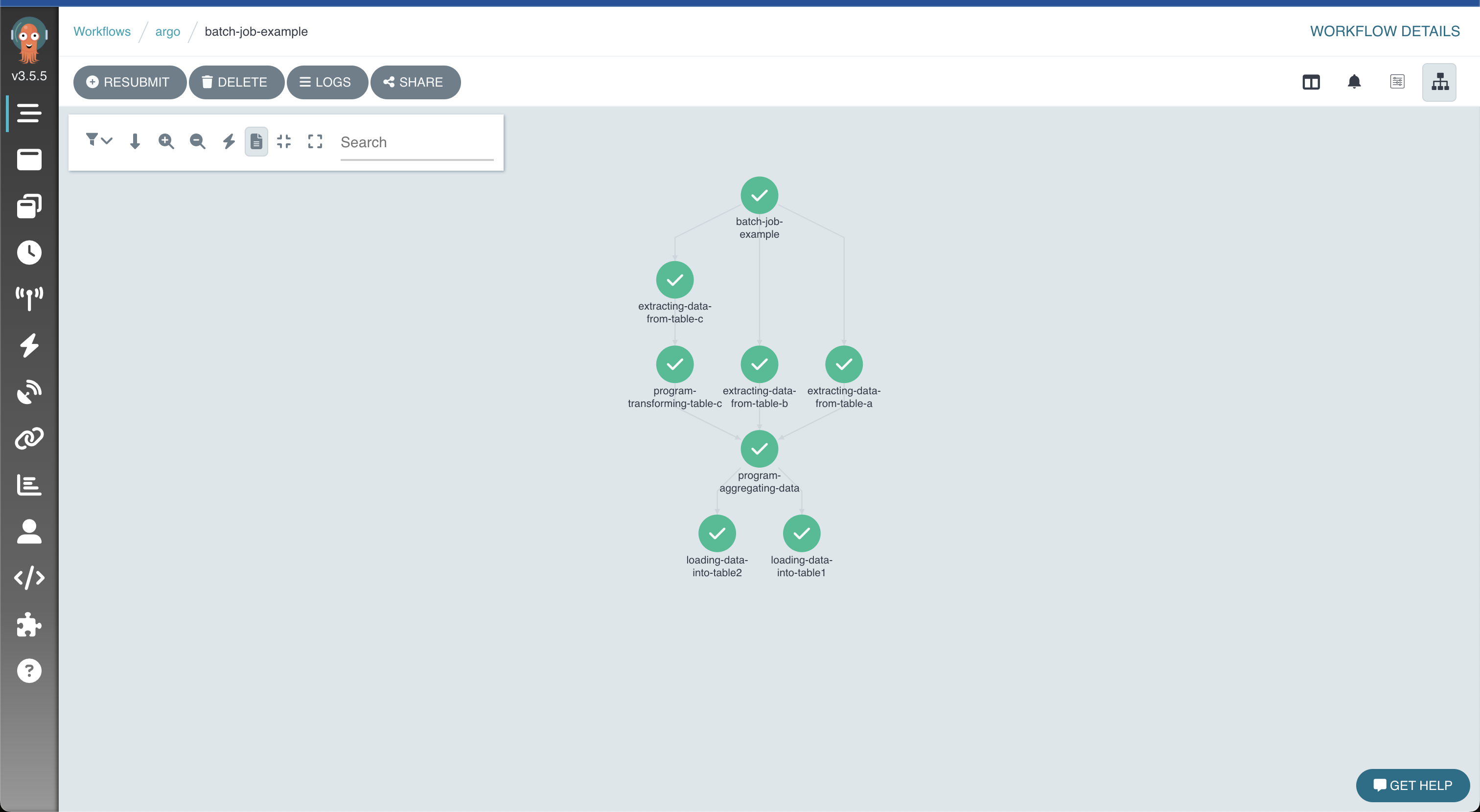
Resultado de la ejecución del proceso representado de manera gráfica en Argo
4.2 - Replicar JES
¿Cómo replicar la funcionalidad del JES?
Si está familiarizado con The Twelve-Factor App, conocerá que uno de sus principios pasa por independizar el código de aplicación de cualquier elemento que pueda variar en el despliegue del mismo en distintos entornos (pruebas, calidad, producción, etc).
Guardar la configuración en el entorno
La configuración de una aplicación es todo lo que puede variar entre despliegues (entornos de preproducción, producción, desarrollo, etc)
The Twelve-Factor App. III Configuraciones
Podemos asimilar la información contenida en los JCLs a ficheros de configuración (config.yml) que contendrán la información necesaria para la ejecución del código en cada uno de los entornos definidos en la instalación (recursos asignados, conexión a la base de datos, nombre y localización de los ficheros de entrada/salida, nivel de detalle del log, etc).
Para entender qué funcionalidad debemos replicar vamos a dividir un JCLs en dos partes:
- Ficha JOB
- Ficha EXEC y DD
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=BCUOTA
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
Ficha JOB
En la ficha JOB, vamos a encontrar la información básica para el “scheduling” del proceso en Kubernetes:
- Información para la clasificación del JOB (CLASS). Permite separar los tipos de JOBs en función de sus características y asignarles parámetros de ejecución distintos
- Definir la salida por defecto (MSGCLASS)
- El nivel de información que se enviará a la salida (MSGLEVEL)
- Cantidad de memoria máxima asignada al proceso (REGION)
- Tiempo máximo estimado para la ejecución del proceso (TIME)
- Información de usuario (USER)
- Etc.
En Kubernetes, el componente kube-scheduler será el encargado de realizar estas tareas, buscando un nodo con las características adecuadas para la ejecución de los pods recién creados. Existen distintas opciones;
- Los procesos Batch pueden usar el Job controller de Kubernetes, este ejecutara un pod por cada paso (STEP) del workflow y lo detendrá una vez finalizada la tarea
- En caso de necesitar funcionalidad más avanzada, por ejemplo para la definición y priorización de distintas colas de ejecución, pueden utilizarse “schedulers” especializados como Volcano
- Por último, es posible desarrollar un controlador kubernetes que se adapte a las necesidades específicas de una instalación
Ficha EXEC y DD
En cada paso (STEP) del JCL podemos encontrar una ficha EXEC y varias fichas DD.
En estas se define el programa (COBOL) a ejecutar y los ficheros de entrada/salida asociados.
A continuación se muestra un ejemplo de cómo transformar un paso (STEP) de un JCL.
---
stepname: "step01"
exec:
pgm: "bcuota"
dd:
- name: "input1"
dsn: "dev/appl1/sample.txt"
disp: "shr"
normaldisp: "catlg"
abnormaldisp: "catlg"
- name: "output1"
dsn: "dev/appl1/cuota.txt"
disp: "new"
normaldisp: "catlg"
abnormaldisp: "delete"
Para la ejecución de programas, las sentencias EXEC y DD se convierten a YAML. Esta información se pasa al controlador d8parti, especializado en la ejecución de programas Batch.
El controlador d8parti actúa como el JES:
- Se encarga de validar la sintaxis del fichero YAML
- Asigna los nombres simbólicos en los programas COBOL a ficheros físicos de entrada/salida
- Carga el programa COBOL en memoria para su ejecución
- Escribe información de monitorización/logging
4.3 - Compilación programas
¿Cómo reutilizar los programas de aplicación del mainframe?
Los programas COBOL PL/I de la plataforma mainframe son directamente reutilizables sobre la plataforma técnica de destino (Linux).
Como hemos comentado anteriormente, el módulo d8parti será el encargado de:
- Inicializar el “runtime” del lenguaje (i.e. COBOL)
- Asignar los ficheros de entrada/salida a los nombres simbólicos del programa
- Cargar y ejecutar el programa principal (definido en la ficha EXEC del JCL)
Este programa principal puede realizar distintas llamadas a otras subrutinas mediante una sentencia CALL, estas llamadas son gestionadas por el “runtime” del lenguaje utilizado
Podemos visualizar este funcionamiento como un árbol invertido
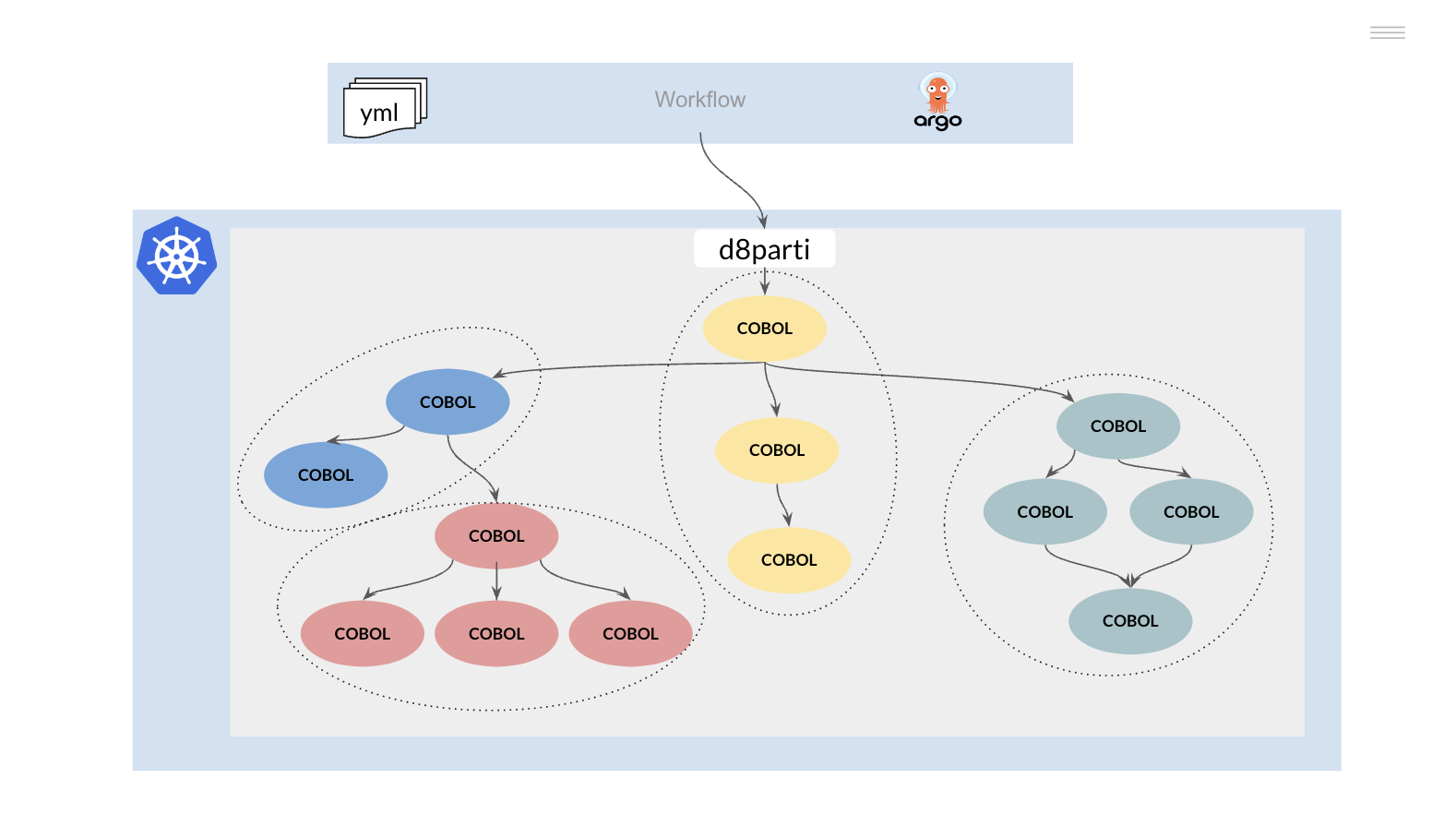
Los programas compilados pueden almacenarse en un directorio compartido y cargarse en tiempo de ejecución (CALL dinámico) replicando el funcionamiento del mainframe IBM (STEPLIB).
Sin embargo, existe la posibilidad de cambiar el comportamiento anterior e implementar un modelo de contenedores inmutables, que presenta ciertas ventajas respecto al modelo anterior. En este caso, el árbol de ejecución anterior debería descomponerse funcionalmente en uno o varios “repos”.
Las modificaciones en alguno de los componentes de estos “repos” generan una nueva versión del mismo y la consiguiente regeneración del contenedor o contenedores que lo utilicen.
Con esta estrategia conseguimos:
- Facilitar el proceso de desarrollo y prueba de las aplicaciones
- Permitir la introducción progresiva de cambios en el sistema, eliminando riesgos
- Posibilitar la portabilidad de los procesos a distintas plataformas (On-prem, On-cloud)
Una vez aislada una función de negocio en un contenedor con una interfaz estándar, este puede modificarse o re-escribirse en cualquier otro lenguaje de programación y desplegarse de manera transparente sin afectar al resto del sistema.
4.4 - Acceso a los datos
¿Cómo acceder a los datos almacenados en ficheros y bases de datos SQL?
Ficheros
En la arquitectura mainframe un Data Set es un conjunto de registros relacionados que se almacenan en una UNIT / VOLUME.
Para entender estos conceptos hay que volver a retroceder en el tiempo, cuando los dispositivos de almacenamiento masivo estaban basados en cintas o cartuchos. Así, cuando un proceso necesitaba acceder a la información de un Data Set, la cinta o cartucho tenía que ser “montada” en una UNIT y era identificado con un nombre o VOLUME.
Hoy en día la información reside en disco y no necesita ser montada/desmontada para su acceso, podemos asimilar los VOLUMEs del mainframe a un “share” de un NFS.
Pueden definirse distintos “puntos de montaje” al contenedor aplicativo para aislar la información y proteger su acceso (por ejemplo por entorno, desarrollo y producción). El acceso se ofrece a los contenedores mediante SDS (Software Define Storage) con el objetivo de poder desacoplar el almacenamiento del proceso.
Por último, los ficheros del mainframe deben transmitirse y convertirse (EBCDIC) a ficheros “Linux” para su utilización en la plataforma destino. Este proceso puede automatizarse mediante herramientas/productos de mercado o usando procesos Spark de conversión de datos.
Base de Datos
El principal motor de Base de Datos del mainframe es el IBM DB2, aunque se siguen utilizando de manera residual otro tipo de productos (IMS DB, IDMS, Adabas).
En el caso de las aplicaciones DB2. Existen dos grandes estrategias bien diferenciadas para el acceso a los datos:
- Réplica de los datos DB2 sobre una nueva Base de Datos SQL (por ejemplo, PostgreSQL)
- Acceso al DB2 de la plataforma mainframe desde el cluster Kubernetes mediante el proxy de convivencia
En el primer caso, los datos de las tablas DB2 se replican sobre un nuevo gestor usando herramientas de replicación (i.e. IBM CDC) o procesos ETL (por ejemplo usando Spark).
Las sentencias SQL DB2 (EXEC SQL … END-EXEC.) se pre-compilan para poder acceder al nuevo gestor de base de datos, es necesario realizar pequeños cambios en el SQL para adaptarlo, sin embargo existe metodología y herramientas para la realización de este proceso de manera automática:
- Réplica del DDL (Tablespaces, Tablas, Índices, Columnas, etc.)
- Adaptación tipos de datos DATE/TIME
- SQLCODEs
- Utilidades de carga y descarga
- Etc
El principal inconveniente de esta estrategia es la necesidad de mantener la integridad de datos del modelo, generalmente el modelo de integridad referencial de la base de datos no está definido en el gestor DB2, debe deducirse por la lógica de las aplicaciones.
Todos los procesos de lectura/actualización que accedan a las tablas afectadas (independientemente de si son Batch/Online) deben ser migrados a la nueva plataforma o definir un mecanismo de convivencia/réplica entre plataformas (Mainframe DB2 / Next-gen SQL) que mantenga la integridad de los datos en ambas hasta la finalización del proceso de migración.
Esta convivencia se hace especialmente crítica en el caso de tablas con datos maestros accedidos por un elevado número de aplicaciones.
En caso de optar por seguir accediendo al DB2 mainframe mediante el proxy de convivencia no es necesario mantener la integridad de los datos entre plataformas (Mainframe / Next-gen). Los procesos (Online o Batch) se pueden migrar individualmente y de manera progresiva (canary deployment)
Una vez finalizado el proceso de migración de los programas de aplicación (Online y Batch) puede realizarse una migración de datos hacia una nueva Base de Datos en la plataforma destino (Next-gen).