A continuación se describen los principales componentes de la arquitectura Batch de IBM, es importante entender las capacidades de cada uno de ellos para replicarlas sobre una arquitectura open basada en contenedores.
- JCL
- JES
- Programas de aplicación (COBOL, PL/I, etc.)
- Datos (Ficheros y Bases de Datos.)
JCL
Podemos pensar en un JCL como un antepasado lejano de un DAG (Directed Acrylic Graph), es un conjunto de sentencias, heredadas de la tecnología de las fichas perforadas, que definen el proceso y la secuencia de pasos a ejecutar.
En el JCL vamos a encontrar las características básicas del proceso o job (nombre, tipo, prioridad, recursos asignados, etc.), la secuencia de programas a ejecutar, las fuentes de información de entrada y qué hacer con los datos de salida del proceso.
Las principales sentencias que encontraremos en un JCL son las siguientes;
- Una ficha JOB, donde se define el nombre del proceso y sus características
- Una o varias fichas EXEC con cada programa que debe ser ejecutado
- Una o varias fichas DD, con la definición de los ficheros (Data Sets) utilizados por los programas anteriores
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=PROGRAM1
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JES
El JES es el componente (subsistema) del Z/OS que se encarga de procesar el Batch. Realiza dos tareas principales:
- La planificación (scheduling) de los procesos Batch
- Asignación del proceso a una clase o iniciador (los jobs pueden asignarse a colas específicas)
- Definir la prioridad del proceso
- Asignar/limitar los recursos asignados al proceso (memoria, tiempo, etc.)
- Controlar el flujo de ejecución de los pasos (STEPs) del proceso
- La ejecución de los programas
- Validación de las sentencias del JCL
- Cargar los programas (COBOL, PL/I) en memoria para su posterior ejecución
- Asignación de los ficheros de entrada/salida a los nombres simbólicos definidos en los programas de aplicación COBOL PL/I
- Logging
Programas de aplicación
Programas, generalmente codificados usando COBOL, que implementan la funcionalidad del proceso.
El ejecutable resultado de la compilación del código fuente se almacena como un miembro de una librería particionada (PDS). Las librerías desde donde cargar los programas se identifican mediante una ficha específica en el JCL (JOBLIB / STEPLIB).
El JES invocará al programa principal del proceso (definido en la ficha EXEC del JCL) y este a su vez podrá llamar a distintas subrutinas de manera estática o dinámica.
Datos
El acceso a los datos se realiza principalmente mediante la utilización de ficheros (Data Sets) y Bases de Datos relacionales (DB2).
Los ficheros de entrada/salida se definen en los programas con un nombre simbólico.
SELECT LOAN ASSIGN TO "INPUT1"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
La asignación de los nombres simbólicos a ficheros de lectura/escritura se realiza en el JCL, mediante la ficha DD.
//*
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
Los ficheros generalmente son de tipo;
- Secuencial, los registros deben ser accedidos de manera secuencial, es decir, para leer el registro 1.000 previamente han leerse los anteriores 999 registros
- VSAM. Existen distintos tipos de ficheros VSAM, siendo posible acceder a los registros directamente mediante mediante una clave (KSDS) o número de registro (RRDS)
En el caso de que el programa necesite acceder a una Base de Datos (DB2), la información necesaria para la conexión (seguridad, nombre de la Base de Datos, etc.) se pasa como parámetros en el JCL.
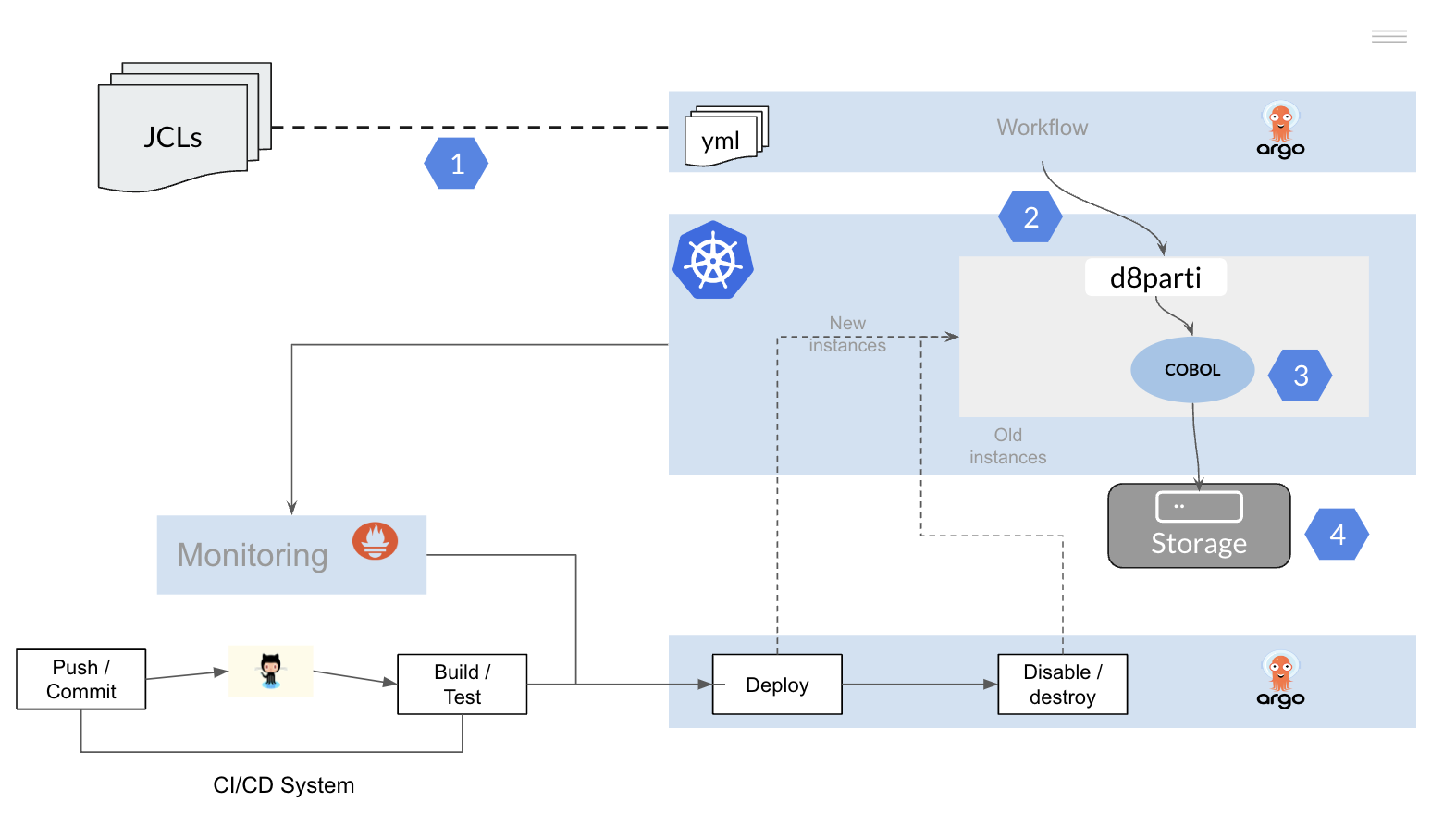
Migración del Batch mainframe a una arquitectura open
Para la migración de los procesos Batch construidos sobre tecnología mainframe vamos a replicar la funcionalidad descrita anteriormente sobre un clúster Kubernetes.
Es necesario por tanto;
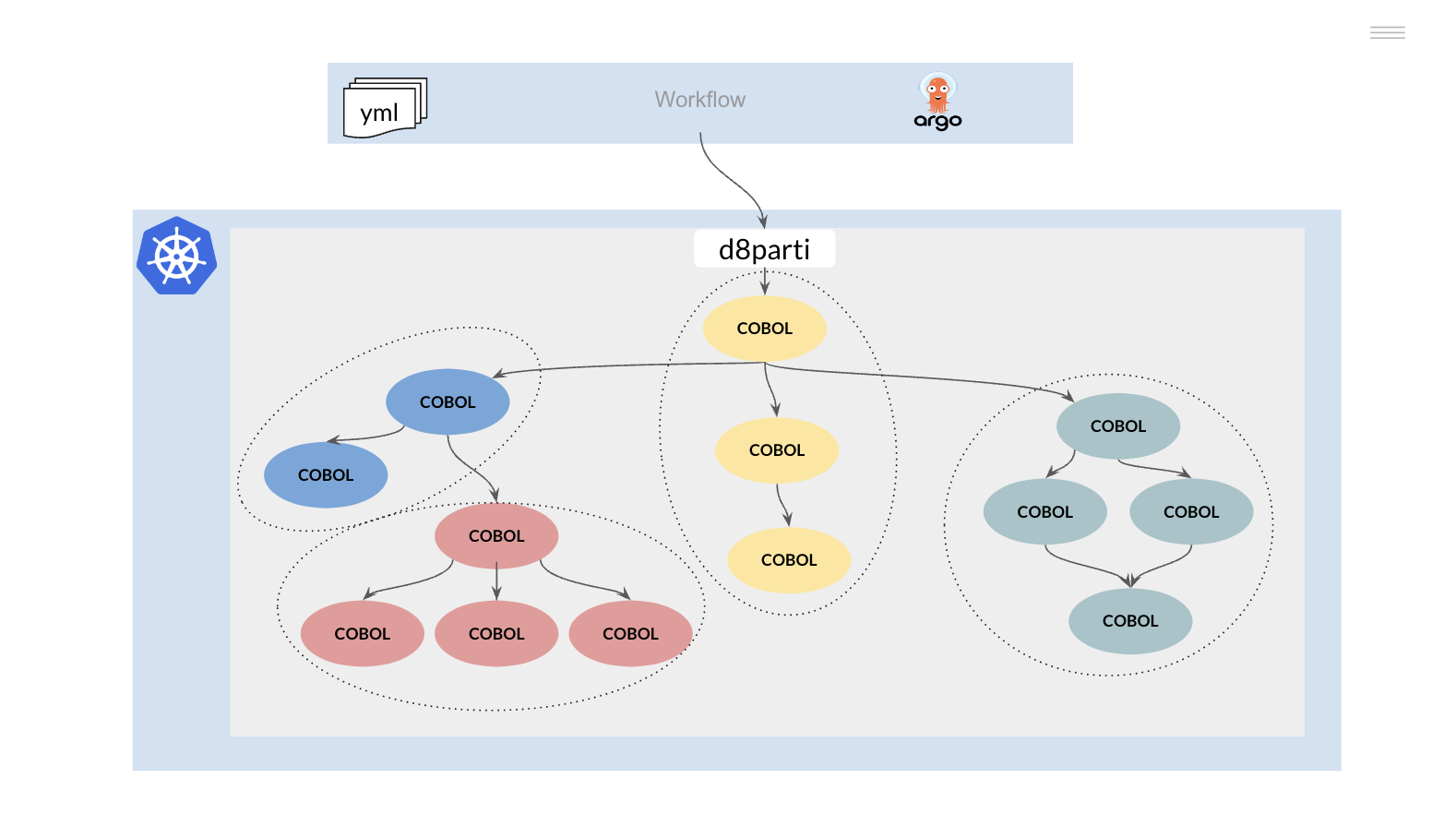
- Convertir los JCLs (JOBs) a una herramienta o framework que permita la ejecución de workflows sobre una plataforma Kubernetes
- Replicar las funcionalidad del JES para permitir el scheduling y ejecución de los programas COBOL PL/I sobre el cluster Kubernetes
- Recompilar los programas de aplicación
- Permitir el acceso a los datos (ficheros y Bases de Datos)