Documentación
Descubra cómo funcionan los principales subsistemas en una arquitectura IBM Mainframe y su equivalencia en una arquitectura Cloud moderna, aprenda a compilar un programa COBOL en una plataforma intel/arm y desplegarlo como una API, encuentre ejemplos y documentación adicional, etc.
El proyecto actualmente se encuentra en fase de desarrollo, si desea colaborar en el mismo o realizar un piloto contacte con nosotros a través de los canales disponibles.
1 - Introducción
Despliegue su código COBOL como microservicios en una arquitectura de Cloud híbrida
¿Qué es driver8?
driver8 es un proyecto que permite reutilizar los activos desarrollados en una arquitectura IBM mainframe para ejecutarlos en una arquitectura Cloud.
Existen distintas alternativas para la migración de aplicaciones mainframe a una arquitectura cloud nativa:
driver8 permite combinar las anteriores alternativas, de acuerdo a las necesidades del proyecto
Rebuild
Las aplicaciones mainframe pueden ser rediseñadas y reescritas (java, python, go, …) como microservicios. Estos nuevos microservicios pueden desplegarse gradualmente al permitirse la convivencia entre plataformas mediante dos mecanismos básicos;
- El acceso a los datos en tiempo real (proxy acceso a la base de datos mainframe DB2)
- La ejecución de transacciones bajo los monitores CICS/IMS
Refactor
El código COBOL puede recompilarse y exponerse como microservicios. Estos microservicios heredan toda la funcionalidad de la plataforma técnica (autorización, cifrado, monitorización, automatización despliegues, etc) y pueden comunicarse con cualquier otro microservicio independientemente del lenguaje de programación utilizado (COBOL, java, python, go,…)
Replace
Por último, la funcionalidad puede sustituirse por un paquete o desarrollo de terceros. Los microservicios pueden comunicarse de manera sencilla con las APIs proporcionadas por el producto
El código desarrollado en un servidor mainframe sigue implementando funciones críticas en muchos negocios, por ejemplo en la industria financiera la mayoría de los procesos contables y la operativa de productos, sigue basándose en tecnología IBM mainframe
La reescritura de miles de programas o la sustitución de dicha funcionalidad por un producto de terceros es en muchos casos inviable por el coste, riesgo y plazo de la iniciativa
En este caso, el código puede reutilizarse en una plataforma open para beneficiarse de las ventajas que ofrece una arquitectura cloud híbrida
¿Qué aplicaciones son ideales para su migración?
En principio cualquier aplicación mainframe online o batch es susceptible de ser migrada, sin embargo, determinadas aplicaciones son más sencillas de migrar. A continuación se enumeran una serie de criterios sencillos que pueden tenerse en cuenta para determinar las aplicaciones candidatas a ser migradas;
- La existencia de arquitecturas técnicas en los monitores transaccionales CICS/IMS
La existencia de una arquitectura técnica independiza a los programas de aplicación de las complejidades del monitor utilizado (send/receive de mensajes, logging, gestión errores, etc.).
Los programas no ejecutan sentencias CICS/IMS y pueden ser compilados directamente.
Facilita el acceso en tiempo real a los datos mediante los drivers del producto (jdbc, odbc), así como la conversión de las sentencias SQL a otro gestor de base de datos relacional.
- Procesamiento batch mediante ficheros secuenciales (QSAM)
Los ficheros pueden transmitirse fácilmente y ejecutar los procesos en paralelo en ambas plataformas para comprobar los resultados
¿Qué debería analizar antes de su migración?
Inventario de aplicaciones
La existencia de miles de componentes (fuentes, copys, JCLs, etc) en la herramienta de gestión de cambios mainframe no implica que dichos componentes estén en uso.
Es necesario realizar un inventario detallado de los componentes activos en la instalación antes de proceder a la migración de los mismos.
Relación entre componentes
Las relaciones entre componentes permiten identificar “repos” aplicativos que posteriormente serán desplegados de manera conjunta
Desconocimiento, ausencia de documentación
Aunque es posible realizar un paralelo de la funcionalidad migrada mediante la comparación binaria de las salidas del proceso (mensajes, ficheros, etc), la aplicación deberá seguir manteniéndose en la nueva arquitectura técnica.
Salvo aplicaciones en sunset sin modificaciones, el disponer de un equipo formado es imprescindible para garantizar con éxito el mantenimiento correctivo/evolutivo del software así como para facilitar el proyecto de migración.
Ficheros VSAM
El funcionamiento de este tipo de ficheros puede reproducirse en la plataforma destino (Berkley DB), sin embargo suponen un nivel de complejidad adicional que podría evitarse migrando los datos y aplicaciones hacia una base de datos SQL.
Los campos del fichero se convierten a columnas y dependiendo del tipo de fichero:
- KSDS, las clave se transforma en un índice único cluster
- RRDS, se usa como índice cluster un contador
- ESDS, en este caso de ordena la tabla mediante un TIMESTAMP
Otros lenguajes de programación
Aunque la mayoría de los desarrollos sobre la plataforma mainframe se realizan usando el lenguaje de programación COBOL, pueden existir aplicaciones que usen programas o rutinas escritas en:
- PL/I. Los programas PL/I pueden compilarse y ejecutarse como microservicios usando la misma arquitectura utilizada por los programas COBOL, sin embargo no existe un compilador PL/I “open” siendo necesario utilizar un producto de terceros con licencia
- Assembler. Las rutinas assembler deben ser convertidas a código C o Go
EBCDIC
La plataforma mainframe utiliza EBCDIC, aunque es posible seguir utilizando EBCDIC sobre la plataforma Linux (intel/arm) en los programas COBOL migrados, esta opción presenta serios inconvenientes de compatibilidad y evolución por lo que descartamos su uso.
Los programas COBOL deben ser analizados para detectar sentencias que impliquen la utilización de datos o caracteres en EBCDIC (por ejemplo, VARIABLE PIC X(3) VALUE X’F1F2F3’).
Aplicaciones 3270
En las transacciones conversacionales o pseudo-conversacionales, el flujo de ejecución/navegación y la presentación está codificada en los programas mainframe, aunque es posible construir un “controlador 3270” este tipo de transacciones tienen una usabilidad limitada por el protocolo que implementan (SNA LU2), siendo difícil su reutilización en canales digitales en los que sea importante la experiencia del usuario final
¿Qué tipo de tecnología no está soportada?
- Gestor de base de datos IMS/DB.
- Herramientas 4GL, Natural/Adabas, IDMS, CA-gen, etc.
Si está interesado en alguna de estas tecnologías o desea colaborar en el desarrollo de la misma, háganoslo saber
Si quiere conocer más sobre driver8
2 - Comience a usar driver8
Exponga un programa COBOL como una moderna API REST
Aquí aprenderá como reutilizar un programa COBOL, exponiéndolo como una API REST moderna. Para ello, le enseñaremos a:
- Instalar un compilador COBOL open (en caso de que no disponga de uno).
- Escribir una sencilla “Hello, world” subrutina COBOL.
- Compilar la subrutina COBOL y probarla.
- Construir una API REST con el código anterior.
Pre-requisitos
- Experiencia de programación básica. Aunque el programa “Hello, world” es muy sencillo, es necesario tener los conocimientos necesarios para compilarlo estáticamente.
- Entender como funciona el paquete cgo de Go.
- Una herramienta IDE para editar el código. Como hemos comentado anteriormente, el código es muy sencillo, por lo que cualquier herramienta debería servirnos. VSCode (free) dispone de distintas extensiones, incluido COBOL para facilitarnos este tipo de tareas.
- Una aplicación para ejecutar comandos. Linux o Mac terminal.
Instalar GNUCobol
Necesitaremos un compilador de COBOL.
Lo ideal, es disponer de un compilador de 64-bit, utilizaremos GNUCobol para compilar y ejecutar el siguiente ejemplo.
Es posible utilizar compiladores COBOL de terceros, con o sin licencia, siempre que ofrezcan la posibilidad de llamar al código COBOL desde programas C.
Step1. Si está utilizando MacOS, instale previamente Homebrew
Step2. Instale GNUCobol, abra un terminal y ejecute el siguiente comando (MacOS):
brew install gnu-cobol
Para instalar GNUCobol en Linux ejecute el comando equivalente según el tipo de distribución utilizada.
Step3. Compruebe si la instalación se realizó de manera correcta ejecutando el siguiente comando:
cobc -v
Comenzar a escribir código
- Abrir la aplicación terminal e ir a nuestro home directory.
cd
- Crear un directorio “hello” para nuestro programa COBOL.
mkdir hello
cd hello
-
En la herramienta de IDE (o editor de texto), crear un fichero con el nombre “hello.cbl”.
-
Copiar el siguiente código en el fichero “hello.cbl” y guardarlo.
IDENTIFICATION DIVISION.
PROGRAM-ID. hello.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* In COBOL, you declare variables in the WORKING-STORAGE section
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 INPUT-NAME PIC X(10).
01 OUTPUT-PARM.
05 PARM1 PIC X(07).
05 PARM2 PIC X(10).
PROCEDURE DIVISION USING INPUT-NAME, OUTPUT-PARM.
MOVE "Hello," TO PARM1.
IF INPUT-NAME IS EQUAL TO (SPACES OR LOW-VALUES)
MOVE "World" TO PARM2
MOVE 2 TO RETURN-CODE
ELSE
MOVE INPUT-NAME TO PARM2
MOVE 0 TO RETURN-CODE
END-IF.
GOBACK.
El programa COBOL “hello” (subrutina COBOL) recibe un &nombre (INPUT-NAME) y devuelve “Hello, &nombre” (OUTPUT-PARM). En caso de que &nombre no sea informado, el programa devuelve “Hello, World”.
- Compilar el programa COBOL “hello”.
cobc -c -O -fstatic-call hello.cbl
Este comando creará un objeto hello.o en el directorio hello
- Ahora necesitaremos un programa principal para poder probar nuestra subrutina COBOL. Cree un fichero “launch.cbl” en el mismo directorio y copie el siguiente código:
IDENTIFICATION DIVISION.
PROGRAM-ID. launch.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* Declare program variables
01 INPUT-NAME PIC X(10).
01 OUTPUT-PARM PIC X(17).
PROCEDURE DIVISION.
* code goes here!
DISPLAY "Your name: " WITH NO ADVANCING.
ACCEPT INPUT-NAME.
CALL 'hello' USING INPUT-NAME, OUTPUT-PARM.
DISPLAY OUTPUT-PARM.
DISPLAY "Return Code: " RETURN-CODE.
STOP RUN.
- Compile el programa principal y haga un linkado estático con la subrutina.
cobc -c -x launch.cbl
cobc -x launch.o hello.o
- Para ejecutar el código ejecute el siguiente comando.
./launch
Construya una API REST
Usaremos el lenguaje Go para construir nuestra API REST. El código Go de nuestra API llamará de manera estática a la subrutina COBOL, de manera equivalente a como lo hacía el programa principal “launch.cbl” usando cgo.
- Para ello, necesitaremos instalar Go
Las instrucciones para la instalación de Go sobre las plataformas MacOS y Linux puede encontrarse aquí. Siga las instrucciones e instale la última versión estable de Go.
- Verifique que Go se ha instalado de manera correcta. Para ello, abra un terminal y ejecute el siguiente comando:
go version
- Vamos a crear la siguiente estructura de directorios para almacenar los componentes del proyecto.
├── greetings
│ └── include
│ └── libs
│ go.mod
│ go.sum
│ main.go
greetings -> Go programs
greetings/include -> .h files
greetings/libs -> hello.o (COBOL routine)
Vaya al directorio go/src y teclee los siguientes comandos:
mkdir greetings
mkdir greetings/include
mkdir greetings/libs
- Cree un fichero “go.mod” para manejar las dependencias del código.
cd greetings
go mod init example/greetings
go: creating new go.mod: module example/greetings
go: to add module requirements and sums:
go mod tidy
- Cree un fichero “main.go” utilizando la herramienta IDE o el editor de texto y copie el siguiente código
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": d})
}
- Vamos a ejecutar nuestra primera API Go.
go mod tidy
go run .
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /hello --> main.getName (3 handlers)
[GIN-debug] GET /hello/:name --> main.getName (3 handlers)
[GIN-debug] [WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.
Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.
[GIN-debug] Listening and serving HTTP on localhost:8080
Ya tenemos nuestra API funcionando, abra una sesión nueva de terminal y utilice curl para probarla.
curl http://localhost:8080/hello
curl http://localhost:8080/hello/Hooper
Linkado estático de la API REST con el módulo COBOL
- Ahora modificaremos el programa “main.go” escrito anteriormente.
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
Desde la función “main” del programa Go tendremos que inicializar el “runtime” COBOL.
C.cob_init(C.int(0), nil)
No vamos a pasar ningún argumento, por lo que será más sencillo pasar un puntero con valor null
Ahora necesitamos crear una nueva función para efectuar la llamada al módulo COBOL “hello.o”
o := callhello(d)
- Copie este código, justo encima de la función “main”.
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
- Para utilizar cgo, necesitamos importar el paquete “C”. Copie el siguiente código justo después de la sentencia “package”.
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
El paquete “C” usará las instrucciones definidas como comentarios justo antes de la línea “import C”. No agrupe la sentencia “import C” con la importación de otros paquetes y asegúrese de que se encuentra a justo a continuación de las líneas de comentarios
#cgo CFLAGS: -I${SRCDIR}/include
Defina el directorio donde se encuentran los ficheros “.h”.
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnu-cobol/3.2/lib -lcob
Defina el directorio donde se encuentra el módulo COBOL (hello.o) y el runtime del lenguaje (GNUCobol).
Por favor, revise de acuerdo al gestor de paquetes utilizado, donde está instalado GNUCobol y específicamente la librería “libcob”. Por ejemplo en MacOs con arquitectura arm (chip M1/M2) homebrew puede instalar GNUCobol en el directorio /opt/homebrew/Cellar/gnucobol/3.2/lib
- A continuación el código completo del programa “main.go”.
package main
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
-
Copie el módulo COBOL “hello.o” en el directorio /greetings/libs.
-
Cree un fichero “hello.h” en el directorio /greetings/include.
cd include
Copie el siguiente código en el fichero “hello.h”
extern int hello(char* inputName, char* outputParm);
¡Hagamos una prueba!
-
Si el programa “main.go” sigue ejecutandose, detengalo.
-
Sitúese en el directorio que contiene el programa “main.go” y ejecute el comando:
go run .
- Probemos nuestra API usando curl
curl http://localhost:8080/hello
curl http://localhost:8080/hello/Hooper
Aprenda a escribir APIs gRPC
En este sencillo ejemplo hemos aprendido como reutilizar nuestro código COBOL mediante la funcionalidad que nos ofrece Go. Si quiere seguir aprendiendo, puede revisar otros ejemplos en la siguiente sección: Ejemplos.
3 - Ejemplos
Ejecute código COBOL fuera del mainframe!
Aquí podrá encontrar un conjunto de programas de ejemplo que le permitirán validar técnicamente las posibilidades de migración de su código mainframe a un arquitectura open.
El código se ha simplificado con el objetivo de hacerlo entendible por cualquier persona con unos conocimientos mínimos de programación.
Puede descargarse el código accediendo al siguiente proyecto en GitHub
¿Quiere hacer un piloto con sus programas?
Póngase en contacto con nosotros.
3.1 - Hello World
Convierta un programa COBOL en una API REST.
Cómo darle una nueva vida a su código COBOL, aprenda a construir APIs REST usando Go cgo.
package main
/*
#cgo CFLAGS: -I${SRCDIR}/include
#cgo LDFLAGS: ${SRCDIR}/libs/hello.o -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "hello.h"
extern void cob_init(int argc,char** argv);
*/
import "C"
import (
"net/http"
"unsafe"
"github.com/gin-gonic/gin"
)
func callhello(d string) string {
inputName := C.CString(d)
defer C.free(unsafe.Pointer(inputName))
outputParm := C.CString("")
defer C.free(unsafe.Pointer(outputParm))
returnCode := C.hello(inputName, outputParm)
if returnCode == 0 || returnCode == 2 {
return C.GoString(outputParm)
} else {
return "ERROR FROM COBOL"
}
}
func main() {
C.cob_init(C.int(0), nil)
router := gin.Default()
router.GET("/hello", getName)
router.GET("/hello/:name", getName)
router.Run("localhost:8080")
}
func getName(c *gin.Context) {
d := c.Param("name")
o := callhello(d)
c.IndentedJSON(http.StatusOK, gin.H{"output-parm": o})
}
Para más información consulte Comience a usar driver8.
3.2 - COBOL gRPC server
Construya un gRPC server a partir de la COPYBOOK.
Transforme una COPYBOOK en un mensaje proto.
Sustituya el CICS IMS por un moderno y eficiente mecanismo basado en RPC (HTTP/2, compresión, cifrado, etc.).
En este ejemplo vamos a implementar nuestro programa COBOL “Hello, World” como un servidor gRPC.
IDENTIFICATION DIVISION.
PROGRAM-ID. hello.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
WORKING-STORAGE SECTION.
* Declare program variables
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 RECORD-TYPE.
05 INPUT-NAME PIC X(10).
05 OUTPUT-PARM.
10 PARM1 PIC X(07).
10 PARM2 PIC X(10).
PROCEDURE DIVISION USING RECORD-TYPE.
MOVE "Hello," TO PARM1.
IF INPUT-NAME IS EQUAL TO (SPACES OR LOW-VALUES)
MOVE "World" TO PARM2
MOVE 2 TO RETURN-CODE
ELSE
MOVE INPUT-NAME TO PARM2
MOVE 0 TO RETURN-CODE
END-IF.
GOBACK.
Cree la siguiente estructura de directorios:
├── d8grpc
│ └── hello_client
│ └── hello_server
│ └── hello
│ go.mod
│ go.sum
A continuación crearemos la definición del mensaje proto que nos servirá para exponer la COPYBOOK del programa COBOL. Para ello cree un fichero con el nombre hello.proto en el directorio d8grpc/hello y copie el siguiente fichero.
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8grpc/hello";
package hello;
// d8grpc hello service definition.
service D8grpc {
// Sends a greeting
rpc Hello (MsgReq) returns (MsgRes) {}
}
// The request message containing the user's name.
message MsgReq {
string hello_name = 1;
}
// The response message containing the greetings
message MsgRes {
string response = 1;
}
Los campos de la COPYBOOK COBOL:
Están definidos como tipo CHAR (con longitudes 10 y 17) y se convierten a string.
Para compilar el mensaje proto ejecute el siguiente comando
protoc --go_out=. --go_opt=paths=source_relative \
--go-grpc_out=. --go-grpc_opt=paths=source_relative \
hello/hello.proto
Instale antes la utilidad de compilación de mensajes proto para el lenguaje Go
Para ello siga las siguientes instrucciones
Vamos a crear el servidor gRPC que realizará la llamada a la subrutina COBOL, en este caso la llamada se realizará de manera dinámica. Cree el fichero main.go en el directorio d8grpc/hello_server y copie el siguiente fichero.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
static void* allocArgv(int argc) {
return malloc(sizeof(char *) * argc);
}
*/
import "C"
import (
"context"
"errors"
"flag"
"fmt"
"log"
"net"
"time"
"unsafe"
pb "github.com/driver8soft/examples/d8grpc/hello"
"google.golang.org/grpc"
)
var (
port = flag.Int("port", 50051, "The server port")
)
type server struct {
pb.UnimplementedD8GrpcServer
}
func (s *server) Hello(ctx context.Context, in *pb.MsgReq) (out *pb.MsgRes, err error) {
start := time.Now()
// define argc, argv
c_argc := C.int(1)
c_argv := (*[0xfff]*C.char)(C.allocArgv(c_argc))
defer C.free(unsafe.Pointer(c_argv))
c_argv[0] = C.CString(in.GetHelloName())
// check COBOL program
n := C.cob_resolve(C.CString("hello"))
if n == nil {
err := errors.New("COBOL: program not found")
log.Println(err)
return &pb.MsgRes{}, err
}
//Call COBOL program
log.Println("INFO: program hello started")
ret := C.cob_call(C.CString("hello"), c_argc, (*unsafe.Pointer)(unsafe.Pointer(c_argv)))
log.Printf("INFO: program hello return-code %v", ret)
//COBOL COPYBOOK is converted to Go String using COPYBOOK length
output := C.GoStringN(c_argv[0], 27)
elapsed := time.Since(start)
log.Printf("INFO: Hello elapsed time %s", elapsed)
return &pb.MsgRes{Response: output[9:]}, nil
}
func main() {
flag.Parse()
// d8 Initialize gnucobol
C.cob_init(C.int(0), nil)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("ERROR: failed to listen: %v", err)
}
var opts []grpc.ServerOption
grpcServer := grpc.NewServer(opts...)
pb.RegisterD8GrpcServer(grpcServer, &server{})
log.Printf("INFO: server listening at %v", lis.Addr())
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("ERROR: failed to serve: %v", err)
}
}
Compile la subrutina COBOL mediante el siguiente comando. El resultado será un módulo (shared library) que podremos llamar de manera dinámica desde el servidor Go gRPC mediante cgo.
cobc -m hello.cbl
El fichero resultante (*.so, *.dylib) puede dejarse en el directorio d8grpc/hello_server
Si decide dejar el módulo COBOL en otro directorio recuerde definirlo (export COB_LIBRARY_PATH=/…my_library…/)
Abra un terminal y ejecute el servidor gRPC mediante el siguiente comando
go run .
Por último, crearemos un cliente Go para realizar la llamada a nuestro servicio gRPC COBOL. Cree el fichero main.go en el directorio d8grpc/hello_client y copie el siguiente fichero.
package main
import (
"context"
"flag"
"log"
pb "github.com/driver8soft/examples/d8grpc/hello"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
var (
addr = flag.String("addr", "localhost:50051", "the address to connect to")
)
var (
name = flag.String("name", "", "name")
)
func main() {
flag.Parse()
// Set up a connection to the server.
conn, err := grpc.NewClient(*addr, grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewD8GrpcClient(conn)
// Contact the server and print out its response.
r, err := client.Hello(context.Background(), &pb.MsgReq{HelloName: *name})
if err == nil {
log.Printf("Output: %s", r.GetResponse())
} else {
log.Printf("ERROR: %v", err)
}
}
Para probar nuestro servicio COBOL gRPC abra un nuevo terminal y ejecute el comando.
go run main.go -name=Hooper
3.3 - Playing with PostgreSQL
Un ejemplo COBOL PostgreSQL.
¿El lenguaje COBOL sólo puede acceder a DB2?
En este sencillo ejemplo accederemos a una base de datos PostgreSQL desde un programa COBOL.
Sus programas pueden ser pre-compilados (EXEC SQL) para acceder a distintas bases de datos SQL
- Oracle Pro*Cobol
- IBM DB2 Cobol precompiler
- OpenESQL para PostgreSQL
Para poder ejecutar este programa es necesario instalar PostgreSQL y crear la base de datos de ejemplo (dvdrental). Puede encontrar las instrucciones de como hacerlo aquí.
*****************************************************************
* Connect and get data from PostgreSQL
* Sample DB "dvdrental" table "actor"
*****************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. pgcobol.
AUTHOR.
DATA DIVISION.
WORKING-STORAGE SECTION.
* CONNECT TO POSGRESQL
01 CONN-STR.
05 FILLER PIC X(20) VALUE "dbname=dvdrental ".
05 FILLER PIC X(20) VALUE "user=XXXXXXXX ".
05 FILLER PIC X(20) VALUE "password=XXXXXXX ".
05 FILLER PIC X(20) VALUE "host=localhost ".
05 FILLER PIC X(20) VALUE "port=5432 ".
05 FILLER PIC X(20) VALUE "sslmode=disable ".
05 FILLER PIC X(01) VALUE LOW-VALUES.
01 CONNECTION USAGE POINTER.
01 CONN-STATUS USAGE BINARY-LONG.
* DECLARE CURSOR
01 SQL-QUERY.
05 SQL-QUERY-DATA PIC X(4096) VALUE SPACES.
05 FILLER PIC X(01) VALUE LOW-VALUES.
01 DB-CURSOR USAGE POINTER.
* SQL ERROR
01 SQL-STATUS USAGE BINARY-LONG.
01 SQL-ERROR-PTR USAGE POINTER.
01 SQL-ERROR-STR PIC X(4096) BASED.
01 SQL-ERROR-MSG PIC X(100) VALUE SPACES.
* COUNTER
01 ROW-COUNTER USAGE BINARY-LONG.
01 COLUMN-COUNTER USAGE BINARY-LONG.
* FETCH
01 RESULT-PTR USAGE POINTER.
01 RESULT-STR PIC X(4096) BASED.
01 RESULT-DATA PIC X(4096) VALUE SPACES.
01 TABLE-ROW.
02 actor_id PIC 9(4) VALUE ZEROS.
02 first_name PIC X(45) VALUE SPACES.
02 last_name PIC X(45) VALUE SPACES.
02 last_update PIC X(22) VALUE SPACES.
* AUX VARIABLES
01 DB-ROW PIC 9(7) VALUE ZEROS.
01 DB-COLUMN PIC 9(3) VALUE ZEROS.
*> *********************************************************************
PROCEDURE DIVISION.
PERFORM CONNECT-DB.
MOVE "SELECT actor_id, first_name, " &
"last_name, last_update " &
"FROM actor;"
TO SQL-QUERY-DATA.
PERFORM DECLARE-CURSOR.
PERFORM ROW-COUNT.
PERFORM COLUMN-COUNT.
* ITERATE OVER ROWS
PERFORM VARYING DB-ROW FROM 0 BY 1
UNTIL DB-ROW >= ROW-COUNTER
PERFORM VARYING DB-COLUMN FROM 0 BY 1
UNTIL DB-COLUMN >= COLUMN-COUNTER
PERFORM ROW-FETCH
END-PERFORM
DISPLAY actor_id " - "
first_name " - "
last_name " - "
last_update
END-PERFORM.
PERFORM DISCONNECT.
GOBACK.
*
CONNECT-DB.
* CONNECT AND CHECK DB STATUS
CALL "PQconnectdb" USING CONN-STR
RETURNING CONNECTION.
CALL "PQstatus" USING BY VALUE CONNECTION
RETURNING CONN-STATUS.
IF CONN-STATUS NOT EQUAL 0 THEN
DISPLAY "Connection error! " CONN-STATUS
STOP RUN
END-IF.
DISCONNECT.
* CLOSE CONNECTION DB
CALL "PQfinish" USING BY VALUE CONNECTION
RETURNING OMITTED.
DECLARE-CURSOR.
* OPEN CURSOR
CALL "PQexec" USING BY VALUE CONNECTION
BY REFERENCE SQL-QUERY
RETURNING DB-CURSOR END-CALL.
CALL "PQresultStatus" USING BY VALUE DB-CURSOR
RETURNING SQL-STATUS.
CALL "PQresStatus" USING BY VALUE SQL-STATUS
RETURNING SQL-ERROR-PTR.
SET ADDRESS OF SQL-ERROR-STR TO SQL-ERROR-PTR.
STRING SQL-ERROR-STR DELIMITED BY x"00"
INTO SQL-ERROR-MSG
END-STRING.
IF SQL-STATUS NOT EQUAL 2 THEN
DISPLAY "Open Cursor error! " SQL-STATUS SQL-ERROR-MSG
STOP RUN
END-IF.
DISPLAY "sql_status: " SQL-STATUS
" sql_error: " SQL-ERROR-MSG.
ROW-COUNT.
* GET NUMBER OF ROWS
CALL "PQntuples" USING BY VALUE DB-CURSOR
RETURNING ROW-COUNTER.
DISPLAY "number of rows: " ROW-COUNTER.
COLUMN-COUNT.
* GET NUMBER OF COLUMNS
CALL "PQnfields" USING BY VALUE DB-CURSOR
RETURNING COLUMN-COUNTER.
DISPLAY "number of fields: " COLUMN-COUNTER.
ROW-FETCH.
*> FETCH
CALL "PQgetvalue" USING BY VALUE DB-CURSOR
BY VALUE DB-ROW BY VALUE DB-COLUMN
RETURNING RESULT-PTR END-CALL
SET ADDRESS OF RESULT-STR TO RESULT-PTR
INITIALIZE RESULT-DATA.
STRING RESULT-STR DELIMITED BY x"00"
INTO RESULT-DATA END-STRING.
EVALUATE DB-COLUMN
WHEN 0
MOVE RESULT-DATA TO actor_id
WHEN 1
MOVE RESULT-DATA TO first_name
WHEN 2
MOVE RESULT-DATA TO last_name
WHEN 3
MOVE RESULT-DATA TO last_update
END-EVALUATE.
Recuerde modificar los campos de WORKING CONN-STR con un usuario y password válidos para la conexión a la base de datos
Las funciones utilizadas por el programa COBOL necesitan la librería de postgreSQL “libpq”, localice donde está instalada dicha librería y añadala en el momento de compilar el programa, por ejemplo:
cobc -x pgcobol.cbl -L/Library/postgreSQL/16/lib -lpq
3.4 - Calling COBOL containers
Llame a programas COBOL remotos.
De manera equivalente al mecanismo del CICS para llamar a programas remotos (EXEC CICS LINK), realice llamadas entre programas COBOL desplegados en distintos contenedores.
A continuación se describe gráficamente el flujo de ejecución
loanmain.cbl <–> d8link.go <———————–> main.go <–> loancalc.cbl
- El programa COBOL loanmain.cbl realiza una llamada (CALL) al conector gRPC d8link, esta simula una sentencia EXEC CICS LINK:
- Se define el programa al que se quiere llamar
- El área de intercambio de datos (COMMAREA)
- Y la longitud de la misma
- El conector gRPC d8link recibe los datos (COMMAREA) y llama al microservicio COBOL correspondiente
- El controller gPRC (main.go) gestiona el mensaje proto, lo convierte a una estructura compatible y llama al programa COBOL loancalc.cbl
- El programa COBOL actualiza el área de datos y devuelve el control al controlador gRPC
- Los datos son envíados de vuelta al conector d8link que los copia sobre el área de memoria definida por el programa COBOL
Cree una estructura de directorios como la siguiente:
├── d8link
│ └── link_client
│ └── link_server
│ └── link
│ go.mod
│ go.sum
En el directorio link definiremos nuestro mensaje proto (link.proto)
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8link/link";
package link;
// The Link service definition.
service LinkService {
rpc CommArea (CommReq) returns (CommResp) {}
}
// The request message containing program to link, commarea and commarea length.
message CommReq {
string link_prog = 1;
int32 comm_len = 2;
bytes input_msg = 3;
}
// The response message containing commarea
message CommResp {
bytes output_msg = 1;
}
A continuación crearemos el programa d8link.go sobre el directorio link_client
package main
/*
#include <string.h>
#include <stdlib.h>
*/
import "C"
import (
"context"
"flag"
"log"
"unsafe"
pb "github.com/driver8soft/examples/d8link/link"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
var (
addr = flag.String("addr", "localhost:50051", "the address to connect to")
)
//export D8link
func D8link(c_program *C.char, c_commarea *C.char, c_commlen *C.int) C.int {
flag.Parse()
// C variables to Go variables
program := C.GoStringN(c_program, 8) // max length of COBOL mainframe program = 8
commarea := C.GoBytes(unsafe.Pointer(c_commarea), *c_commlen)
commlen := int32(*c_commlen)
log.Println("INFO: Call program -", program)
// Set up a connection to the server.
conn, err := grpc.NewClient(*addr, grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewLinkServiceClient(conn)
// Contact the server
r, err := client.CommArea(context.Background(), &pb.CommReq{LinkProg: program, CommLen: commlen, InputMsg: commarea})
if err != nil {
log.Fatalf("ERROR: calling program - %s - %v", program, err)
}
outMsg := r.GetOutputMsg()
C.memcpy(unsafe.Pointer(c_commarea), unsafe.Pointer(&outMsg[0]), C.size_t(commlen))
return 0
}
func main() {
}
Vamos a exportar la función D8link para que pueda ser llamada desde un programa COBOL, para ello es necesario compilarla utilizando la opción c-shared de Go
El compilador de Go generará un objeto (D8link.dylib D8link.so) y un fichero (D8link.h) que serán llamados dinámicamente desde el código COBOL
Y para finalizar crearemos el servidor gRPC (main.go) en el directorio link_server que será el encargado de recibir el mensaje proto y llamar al programa COBOL destino.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
static void* allocArgv(int argc) {
return malloc(sizeof(char *) * argc);
}
*/
import "C"
import (
"context"
"flag"
"fmt"
"log"
"net"
"strings"
"time"
"unsafe"
pb "github.com/driver8soft/examples/d8link/link"
"google.golang.org/grpc"
)
var (
port = flag.Int("port", 50051, "The server port")
)
type server struct {
pb.UnimplementedLinkServiceServer
}
func (s *server) CommArea(ctx context.Context, in *pb.CommReq) (out *pb.CommResp, err error) {
start := time.Now()
// remove trailing spaces from program name
program := strings.TrimSpace(in.GetLinkProg())
c_program := C.CString(program)
defer C.free(unsafe.Pointer(c_program))
c_commlen := C.int(in.GetCommLen())
// allocate argc & argv variables
c_argc := C.int(1)
c_argv := (*[0xfff]*C.char)(C.allocArgv(c_argc))
defer C.free(unsafe.Pointer(c_argv))
c_argv[0] = C.CString(string(in.GetInputMsg()))
defer C.free(unsafe.Pointer(c_argv[0]))
// check COBOL program
n := C.cob_resolve(c_program)
if n == nil {
log.Println("ERROR: Module not found. Program name =", program)
} else {
log.Printf("INFO: %s started", program)
ret := C.cob_call(c_program, c_argc, (*unsafe.Pointer)(unsafe.Pointer(c_argv)))
log.Printf("INFO: %s return-code %v", program, ret)
}
c_msg_output := C.GoStringN(c_argv[0], c_commlen)
elapsed := time.Since(start)
log.Printf("INFO: %s elapsed time %s", program, elapsed)
return &pb.CommResp{OutputMsg: []byte(c_msg_output)}, nil
}
func main() {
flag.Parse()
// d8 Initialize gnucobol
C.cob_init(C.int(0), nil)
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("ERROR: failed to listen: %v", err)
}
grpcServer := grpc.NewServer()
pb.RegisterLinkServiceServer(grpcServer, &server{})
log.Printf("INFO: server listening at %v", lis.Addr())
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("ERROR: failed to serve: %v", err)
}
}
Pruebe a realizar llamadas remotas entre programas COBOL intercambiando un área de datos (COPYBOOK).
Para ello recuerde que:
- El programa llamador debe compilarse para generar un ejecutable (opción -x GNUCobol)
- El programa llamado debe compilarse para generar un objeto (opción -m GNUCobol)
- Ambos programas deben compilarse utilizando el mismo “byteorder” para compartir datos binarios
- Para simplificar la prueba los programas COBOL puede residir en los directorios definidos anteriormente (link_client link_server)
Puede utilizar los programas COBOL de ejemplo loanmain.cbl y loancalc.cbl.
******************************************************************
*
* Loan Calculator Main Program
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loanmain.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 PROG-NAME PIC X(8) VALUE "loancalc".
01 COMMLEN PIC 9(9) COMP.
01 COMMAREA.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION.
* code goes here!
INITIALIZE COMMAREA.
DISPLAY "Compound Interest Calculator"
DISPLAY "Principal amount: " WITH NO ADVANCING.
ACCEPT PRIN-AMT.
DISPLAY "Interest rate: " WITH NO ADVANCING.
ACCEPT INT-RATE.
DISPLAY "Number of years: " WITH NO ADVANCING.
ACCEPT TIMEYR.
COMPUTE COMMLEN = LENGTH OF COMMAREA.
CALL "D8link" USING PROG-NAME COMMAREA COMMLEN.
DISPLAY "Error Msg: " ERROR-MSG.
DISPLAY "Couta: " PAYMENT.
GOBACK.
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
DISPLAY "PRIN-AMT: " PRIN-AMT.
DISPLAY "INT-RATE: " INT-RATE.
DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
DISPLAY "PAYMENT: " PAYMENT.
DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
3.5 - COBOL & Kafka
Convierta su programa COBOL en un Kafka consumer/producer.
Quiere integrar sus programas COBOL en un modelo de proceso basado en eventos.
Aprenda cómo convertir un programa COBOL en un Kafka consumer / producer.
Desde el programa COBOL realizaremos una llamada al módulo D8kafka pasándole:
- El topic Kafka
- Una lista de valores (key : value) separados por comas
******************************************************************
*
* Loan kafka producer
* ==========================
*
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. cuotak.
ENVIRONMENT DIVISION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
01 WS-LOAN.
05 WS-AMT PIC 9(7)V9(2).
05 WS-INT PIC 9(2)V9(2).
05 WS-YEAR PIC 9(2).
******************************************************************
01 KAFKA.
05 KAFKA-TOPIC PIC X(05) VALUE "loans".
05 FILLER PIC X(1) VALUE LOW-VALUES.
05 KAFKA-KEY.
10 KAFKA-KEY1 PIC X(15) VALUE "PrincipalAmount".
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-KEY2 PIC X(12) VALUE "InterestRate".
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-KEY1 PIC X(09) VALUE "TimeYears".
10 FILLER PIC X(1) VALUE LOW-VALUES.
05 KAFKA-VALUE.
10 KAFKA-AMT-VALUE PIC zzzzzz9.99.
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-INT-VALUE PIC z9.99.
10 FILLER PIC X(1) VALUE ",".
10 KAFKA-YEAR-VALUE PIC zz.
10 FILLER PIC X(1) VALUE LOW-VALUES.
PROCEDURE DIVISION.
INITIALIZE WS-LOAN.
DISPLAY "Amount: " WITH NO ADVANCING.
ACCEPT WS-AMT.
DISPLAY "Interest: " WITH NO ADVANCING.
ACCEPT WS-INT.
DISPLAY "Number of Years: " WITH NO ADVANCING.
ACCEPT WS-YEAR.
MOVE WS-AMT TO KAFKA-AMT-VALUE.
MOVE WS-INT TO KAFKA-INT-VALUE.
MOVE WS-YEAR TO KAFKA-YEAR-VALUE.
CALL "D8kafka" USING KAFKA-TOPIC
KAFKA-KEY
KAFKA-VALUE.
DISPLAY "Return-code: " RETURN-CODE.
GOBACK.
A continuación se muestra una versión simplificada de ejemplo del módulo d8kafka
package main
/*
#include <string.h>
#include <stdlib.h>
*/
import "C"
import (
"encoding/json"
"fmt"
"os"
"strings"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
type Kdata struct {
Key string `json:"key"`
Value string `json:"value"`
}
//export D8kafka
func D8kafka(c_topic *C.char, c_key *C.char, c_value *C.char) C.int {
keys := strings.Split(C.GoString(c_key), ",")
values := strings.Split(C.GoString(c_value), ",")
data := make([]Kdata, len(keys))
for i := 0; i < len(keys); i++ {
data[i] = Kdata{Key: keys[i], Value: values[i]}
}
KafkaMsg, _ := json.Marshal(data)
topic := C.GoString(c_topic)
p, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:29092",
"client.id": "client",
"acks": "all"},
)
if err != nil {
fmt.Printf("ERROR: Failed to create producer: %s\n", err)
os.Exit(1)
}
delivery_chan := make(chan kafka.Event, 1000)
err = p.Produce(
&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(KafkaMsg),
},
delivery_chan,
)
if err != nil {
fmt.Printf("ERROR: Failed to produce message: %s\n", err)
os.Exit(1)
}
e := <-delivery_chan
m := e.(*kafka.Message)
if m.TopicPartition.Error != nil {
fmt.Printf("ERROR: Delivery failed: %v\n", m.TopicPartition.Error)
} else {
fmt.Printf("INFO: Delivered message to topic %s [%d] at offset %v\n",
*m.TopicPartition.Topic, m.TopicPartition.Partition, m.TopicPartition.Offset)
}
close(delivery_chan)
return 0
}
func main() {
}
Para consumir el topic kafka desde un programa Go puede utilizar el siguiente ejemplo:
package main
import (
"fmt"
"os"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var topic string = "loans"
var run bool = true
func main() {
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "localhost:29092",
"group.id": "sample",
"auto.offset.reset": "smallest"},
)
if err != nil {
fmt.Printf("ERROR: Failed to create consumer: %s\n", err)
os.Exit(1)
}
err = consumer.Subscribe(topic, nil)
if err != nil {
fmt.Printf("ERROR: Failed to subscribe: %s\n", err)
os.Exit(1)
}
for run {
ev := consumer.Poll(100)
switch e := ev.(type) {
case *kafka.Message:
fmt.Printf("INFO: %s", e.Value)
case kafka.Error:
fmt.Printf("%% ERROR: %v\n", e)
run = false
}
}
consumer.Close()
}
Para ejecutar una prueba es necesario tener instalado Kafka
Un manera sencilla de hacerlo es utilizar Docker (docker-compose.yml) para configurar un entorno mínimo de pruebas con zookeeper y kafka
3.6 - JCL to DAG
Transforme un JCL en un fichero de configuración para ejecutar un programa batch.
Vamos a convertir un paso de un JCL en un fichero de configuración (yaml).
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=BCUOTA
//INFILE DD DSN=DEV.APPL1.TEST,DISP=SHR
//OUTFILE DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
Cree un fichero step.yaml y copie el siguiente código.
---
stepname: "step1"
exec:
pgm: "bcuota"
dd:
- name: "infile"
dsn: "test.txt"
disp: "shr"
normaldisp: "catlg"
abnormaldisp: "catlg"
- name: "outfile"
dsn: "cuota.txt"
disp: "new"
normaldisp: "catlg"
abnormaldisp: "delete"
A continuación ejecutaremos un programa batch de lectura/escritura de ficheros usando esta configuración.
El programa principal bcuota.cbl lee un fichero de entrada, llama a la rutina COBOL loancalc.cbl para calcular la cuota a pagar de un préstamo y escribe el resultado en el fichero de salida.
******************************************************************
*
* Loan Calculator Batch
* ==========================
*
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. bcuota.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT LOAN ASSIGN TO "infile"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
SELECT CUOTA ASSIGN TO "outfile"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD LOAN.
01 LOAN-FILE PIC X(26).
FD CUOTA.
01 CUOTA-FILE.
05 CUOTA-ACC PIC X(10).
05 CUOTA-PAY PIC 9(7)V9(2).
WORKING-STORAGE SECTION.
01 WS-LOAN.
05 WS-ACC PIC X(10).
05 FILLER PIC X(1).
05 WS-AMT PIC 9(7).
05 FILLER PIC X(1).
05 WS-INT PIC 9(2)V9(2).
05 FILLER PIC X(1).
05 WS-YEAR PIC 9(2).
01 WS-EOF PIC X(1) VALUE "N".
01 WS-COUNTER PIC 9(9) VALUE ZEROES.
****************************************************************
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION.
OPEN INPUT LOAN.
OPEN OUTPUT CUOTA.
PERFORM UNTIL WS-EOF='Y'
READ LOAN INTO WS-LOAN
AT END MOVE 'Y' TO WS-EOF
NOT AT END
MOVE WS-AMT TO PRIN-AMT
MOVE WS-INT TO INT-RATE
MOVE WS-YEAR TO TIMEYR
CALL "loancalc" USING LOAN-PARAMS
ADD 1 TO WS-COUNTER
MOVE WS-ACC TO CUOTA-ACC
MOVE PAYMENT TO CUOTA-PAY
WRITE CUOTA-FILE
END-WRITE
END-READ
END-PERFORM.
CLOSE LOAN.
CLOSE CUOTA.
DISPLAY "TOTAL RECORDS PROCESSED: " WS-COUNTER.
GOBACK.
La rutina loancalc.cbl se ha modificado para eliminar la escritura en el log del sistema
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
* DISPLAY "PRIN-AMT: " PRIN-AMT.
* DISPLAY "INT-RATE: " INT-RATE.
* DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
* DISPLAY "PAYMENT: " PAYMENT.
* DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
Compile ambos programas para generar una librería compartida (*.so, *dylib)
cobc -m bcouta.cbl loancalc.cbl
El controlador d8parti será el encargado de reemplazar al JES, a continuación se muestra una versión simplificada de dicho módulo, cree un fichero d8parti.go y copie el siguiente código.
package main
/*
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <libcob.h>
#cgo CFLAGS: -I/opt/homebrew/Cellar/gnucobol/3.2/include
#cgo LDFLAGS: -L/opt/homebrew/Cellar/gnucobol/3.2/lib -lcob
*/
import "C"
import (
"fmt"
"log"
"os"
"time"
"unsafe"
"github.com/spf13/viper"
)
type step struct {
Stepname string `mapstructure:"stepname"`
Exec exec
Dd []dd
}
type exec struct {
Pgm string `mapstructure:"pgm"`
}
type dd struct {
Name string `mapstructure:"name"`
Dsn string `mapstructure:"dsn"`
Disp string `mapstructure:"disp"`
Normaldisp string `mapstructure:"normaldisp"`
Abnormaldisp string `mapstructure:"abnormaldisp"`
}
var Step *step
func config() error {
// Read yaml config file
viper.SetConfigName("step")
viper.SetConfigType("yaml")
viper.AddConfigPath(".")
if err := viper.ReadInConfig(); err != nil {
return err
}
// Unmarshal yaml config file
if err := viper.Unmarshal(&Step); err != nil {
return err
}
// Create Symlink
for i := 0; i < len(Step.Dd); i++ {
err := os.Symlink(Step.Dd[i].Dsn, Step.Dd[i].Name)
if err != nil {
switch {
case os.IsExist(err):
// DDNAME already exist
log.Printf("INFO: DDNAME=%s already exists. %s", Step.Dd[i].Name, err)
case os.IsNotExist(err):
// DDNAME invalid
log.Printf("ERROR: DDNAME=%s invalid ddname. %s", Step.Dd[i].Name, err)
return err
default:
log.Println(err)
return err
}
}
}
return nil
}
func cobCall(p string) error {
defer delSymlink()
c_progName := C.CString(p)
defer C.free(unsafe.Pointer(c_progName))
n := C.cob_resolve(c_progName)
if n == nil {
return fmt.Errorf("ERROR: Program %s not found", p)
} else {
log.Printf("INFO: PGM=%s started", p)
r := C.cob_call_with_exception_check(c_progName, C.int(0), nil)
rc := int(C.cob_last_exit_code())
err := C.GoString(C.cob_last_runtime_error())
switch int(r) {
case 0:
log.Printf("INFO: program %s exited with return-code: %v", p, rc)
C.cob_tidy()
case 1:
log.Printf("INFO: program %s STOP RUN with return-code: %v", p, rc)
case -1:
return fmt.Errorf("ERROR: program %s exit with return-code: %v and error: %s", p, rc, err)
case -2:
return fmt.Errorf("FATAL: program %s exit with return-code: %v and error: %s", p, rc, err)
case -3:
return fmt.Errorf("ERROR: program %s signal handler exit with signal: %v and error: %s", p, rc, err)
default:
return fmt.Errorf("ERROR: program %s unexpected return exit code: %v and error: %s", p, rc, err)
}
return nil
}
}
func delSymlink() {
for i := 0; i < len(Step.Dd); i++ {
err := os.Remove(Step.Dd[i].Name)
if err != nil {
log.Printf("INFO: DDNAME=%s does not exists. %s", Step.Dd[i].Name, err)
}
}
}
func main() {
start := time.Now()
// Initialize gnucobol
C.cob_init(C.int(0), nil)
log.Println("INFO: gnucobol initialized")
// Load config file
if err := config(); err != nil {
log.Printf("ERROR: reading yaml config file. %s", err)
os.Exit(12)
}
// Call COBOL program -> EXEC PGM defined in JCL
if err := cobCall(Step.Exec.Pgm); err != nil {
log.Println(err)
os.Exit(12)
}
elapsed := time.Since(start)
log.Printf("INFO: %s elapsed time %s", Step.Exec.Pgm, elapsed)
}
Para ejecutar el programa COBOL batch de pruebas, simplemente abra una consola y ejecute lo siguiente:
go run d8parti.go
¿Como crear un fichero de entrada de ejemplo (infile)?
El formato del fichero de entrada es muy sencillo
01 WS-LOAN.
05 WS-ACC PIC X(10).
05 FILLER PIC X(1).
05 WS-AMT PIC 9(7).
05 FILLER PIC X(1).
05 WS-INT PIC 9(2)V9(2).
05 FILLER PIC X(1).
05 WS-YEAR PIC 9(2).
Consta de un número de cuenta (10 bytes), un importe (7 bytes), un tipo de interés (4 bytes con dos posiciones decimales) y un periodo en años (2 bytes). Los campos se delimitan mediante un separador (FILLER 1 byte) para facilitar la lectura del fichero de entrada.
Puede utilizar el siguiente programa de ejemplo para generar el fichero de entrada.
package main
import (
"flag"
"fmt"
"math/rand"
"os"
"strconv"
"time"
)
var r1 *rand.Rand
var (
rows = flag.Int("rows", 1000, "number of rows to generate")
)
var (
file = flag.String("file", "test.txt", "input file name")
)
func main() {
flag.Parse()
s1 := rand.NewSource(time.Now().UnixNano())
r1 = rand.New(s1)
f, err := os.Create(*file)
if err != nil {
fmt.Println(err)
return
}
for i := 0; i != *rows; i++ {
output := account(i) + "-" + amount() + "-" + interest() + "-" + yearsPending() + "\n"
_, err := f.WriteString(output)
if err != nil {
fmt.Println(err)
f.Close()
return
}
}
err = f.Close()
if err != nil {
fmt.Println(err)
return
}
}
func account(id int) string {
return "id:" + fmt.Sprintf("%07d", id+1)
}
func amount() string {
min := 1000
max := 1000000
a := strconv.Itoa(r1.Intn(max-min+1) + min)
for i := len(a); i != 7; i++ {
a = "0" + a
}
return a
}
func interest() string {
return "0450"
}
func yearsPending() string {
min := 5
max := 25
y := strconv.Itoa(r1.Intn(max-min+1) + min)
if len(y) < 2 {
y = "0" + y
}
return y
}
3.7 - COBOL to Go
Convierta el código COBOL a Go.
Los avances en IA Gen permiten vislumbrar un futuro en el que la conversión de código entre distintos lenguajes de programación pueda realizarse de manera automática y transparente.
Sin embargo, deben tenerse en cuenta las características del lenguaje COBOL para seleccionar una opción que permita reconocer el código convertido de forma que pueda seguir siendo mantenido por el equipo responsable.
Vamos a utilizar la rutina COBOL de ejemplo que calcula la cuota de un préstamo.
******************************************************************
*
* Loan Calculator Subroutine
* ==========================
*
* A sample program to demonstrate how to create a gRPC COBOL
* microservice.
*
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. loancalc.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare program variables
01 WS-MSG.
05 WS-ERROR PIC X(01).
05 WS-MSG00 PIC X(20) VALUE 'OK'.
05 WS-MSG10 PIC X(20) VALUE 'INVALID INT. RATE'.
05 WS-MSG12 PIC X(20) VALUE 'INVALID NUMBER YEARS'.
01 AUX-VARS.
05 MONTHLY-RATE USAGE IS COMP-2.
05 AUX-X USAGE IS COMP-2.
05 AUX-Y USAGE IS COMP-2.
05 AUX-Z USAGE IS COMP-2.
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 LOAN-PARAMS.
05 INPUT-MSG.
10 PRIN-AMT PIC S9(7) USAGE IS DISPLAY.
10 INT-RATE PIC S9(2)V9(2) USAGE IS DISPLAY.
10 TIMEYR PIC S9(2) USAGE IS DISPLAY.
05 OUTPUT-MSG.
10 PAYMENT PIC S9(7)V9(2) USAGE IS DISPLAY.
10 ERROR-MSG PIC X(20).
PROCEDURE DIVISION USING BY REFERENCE LOAN-PARAMS.
* code goes here!
000-MAIN.
MOVE "N" TO WS-ERROR.
DISPLAY "PRIN-AMT: " PRIN-AMT.
DISPLAY "INT-RATE: " INT-RATE.
DISPLAY "TIMEYR: " TIMEYR.
PERFORM 100-INIT.
IF WS-ERROR = 'N'
PERFORM 200-PROCESS
END-IF.
PERFORM 300-WRAPUP.
100-INIT.
IF INT-RATE <= 0
MOVE WS-MSG10 TO ERROR-MSG
MOVE 10 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
ELSE
IF TIMEYR <= 0
MOVE WS-MSG12 TO ERROR-MSG
MOVE 12 TO RETURN-CODE
MOVE 'Y' TO WS-ERROR
END-IF
END-IF.
200-PROCESS.
INITIALIZE AUX-VARS.
COMPUTE MONTHLY-RATE = (INT-RATE / 12 / 100).
COMPUTE AUX-X = ((1 + MONTHLY-RATE) ** (TIMEYR*12)).
COMPUTE AUX-Y = AUX-X * MONTHLY-RATE.
COMPUTE AUX-Z = (AUX-X - 1) / AUX-Y.
COMPUTE PAYMENT = PRIN-AMT / AUX-Z.
MOVE WS-MSG00 TO ERROR-MSG.
MOVE 0 TO RETURN-CODE.
DISPLAY "PAYMENT: " PAYMENT.
DISPLAY "ERROR-MSG: " ERROR-MSG.
300-WRAPUP.
GOBACK.
Una primera aproximación pasa por mantener la estructura del código COBOL:
- Una subrutina COBOL equivale a una función en Go
- Las variables definidas en la WORKING-STORAGE se agrupan y transforman en variables Go
- El código de la PROCEDUCE DIVISION se compone de uno o varias secciones (PARAGRAPHS), estas se pueden transformar a su vez en funciones muy sencillas
- Por último, las variables de la LINKAGE SECTION definen los parámetros de la función principal y se comparten (puntero) entre todas las funciones
// Declare variables in the working storage section
var (
WS_ERROR string
WS_MSG00 string = "OK"
WS_MSG10 string = "INVALID INT. RATE"
WS_MSG12 string = "INVALID NUMBER YEARS"
MONTHLY_RATE float64
AUX_X float64
AUX_Y float64
AUX_Z float64
)
// Data to share with COBOL subroutines
type LoanParams struct {
PrinAmt float64
IntRate float64
TimeYr int32
Payment float64
ErrorMsg string
}
func loancalc(amount float64, interest float64, nyears int32) (payment float64, errmsg string) {
WS_ERROR = "N"
loanParams := LoanParams{
PrinAmt: amount,
IntRate: interest,
TimeYr: nyears,
}
fmt.Println("PRIN-AMT:", loanParams.PrinAmt)
fmt.Println("INT-RATE:", loanParams.IntRate)
fmt.Println("TIMEYR:", loanParams.TimeYr)
initial(&loanParams)
if WS_ERROR == "N" {
process(&loanParams)
}
wrapup(&loanParams)
return loanParams.Payment, loanParams.ErrorMsg
}
func initial(loanParams *LoanParams) {
if loanParams.IntRate <= 0 {
loanParams.ErrorMsg = WS_MSG10
WS_ERROR = "Y"
} else {
if loanParams.TimeYr <= 0 {
loanParams.ErrorMsg = WS_MSG12
WS_ERROR = "Y"
}
}
}
func process(loanParams *LoanParams) {
MONTHLY_RATE = loanParams.IntRate / 12 / 100
AUX_X = math.Pow((1 + MONTHLY_RATE), float64(loanParams.TimeYr*12))
AUX_Y = AUX_X * MONTHLY_RATE
AUX_Z = (AUX_X - 1) / AUX_Y
loanParams.Payment = loanParams.PrinAmt / AUX_Z
loanParams.ErrorMsg = WS_MSG00
}
func wrapup(loanParams *LoanParams) {
fmt.Println("PAYMENT:", loanParams.Payment)
fmt.Println("ERROR-MSG:", loanParams.ErrorMsg)
}
Hay que recordar que el código COBOL ya ha sido expuesto mediante una interfaz estándar que define los parámetros de entrada/salida de la función (por ejemplo, mediante un mensaje proto).
Utilizando la definición de dicha interfaz, es posible volver a refactorizar el código simplificando el resultado final.
func loancalc(amount, interest float64, nyears int32) (payment float64, errmsg string) {
if interest <= 0 {
return 0, "Invalid int. rate"
}
if nyears <= 0 {
return 0, "Invalid number of years"
}
monthlyRate := (interest / 12 / 100)
x := math.Pow((1 + monthlyRate), float64(nyears*12))
y := x * monthlyRate
payment = amount / ((x - 1) / y)
return payment, "OK"
}
3.8 - Python
Desea utilizar Python
La tecnología gRPC nos permite conectar programas escritos en distintos lenguajes de programación de manera sencilla.
En este ejemplo, crearemos un cliente Python para llamar a nuestro servicio gRPC COBOL (hello.cbl).
Para ello primero necesitaremos compilar el mensaje proto para el lenguaje Python.
syntax = "proto3";
option go_package = "github.com/driver8soft/examples/d8grpc/hello";
package hello;
// d8grpc hello service definition.
service D8grpc {
// Sends a greeting
rpc Hello (MsgReq) returns (MsgRes) {}
}
// The request message containing the user's name.
message MsgReq {
string hello_name = 1;
}
// The response message containing the greetings
message MsgRes {
string response = 1;
}
Instale el compilador correspondiente al lenguaje Python y ejecute el siguiente comando
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. hello.proto
La compilación del fichero proto creará los stubs necesarios para nuestro cliente Python
- hello_pb2.py
- hello_pb2_grpc.py
A continuación crearemos un cliente Python gRPC, cree un fichero client.py y copie el siguiente código.
import grpc
import hello_pb2
import hello_pb2_grpc
def run(inputname):
with grpc.insecure_channel('localhost:50051') as channel:
stub = hello_pb2_grpc.D8grpcStub(channel)
r = stub.Hello(hello_pb2.MsgReq(hello_name=inputname))
print(f"Result: {r.response}")
if __name__ == '__main__':
# Get user Input
inputname = input("Please enter name: ")
run(inputname)
Para probar el nuevo cliente Python, abra un terminal y ejecute
python client.py
4 - Conceptos básicos
Cómo desmontar un mainframe IBM … y no morir en el intento
Un servidor IBM mainframe está diseñado como una arquitectura monolítica altamente acoplada. Los programas de aplicación se comunican entre ellos y con los repositorios de datos mediante el intercambio de direcciones de memoria (punteros).
¿Cómo es posible desmontar este monolito de manera progresiva y segura para minimizar los riesgos del proceso?
4.1 - Strangler Fig Pattern
¿Cómo desmontar una arquitectura monolítica de manera segura?
El servidor IBM mainframe es un sistema monolítico, no existe una separación clara entre los distintos niveles o capas de la arquitectura técnica, todos los procesos residen en la misma máquina (CICS, Batch, Base de Datos, etc).
La comunicación entre los distintos procesos (llamadas entre programas, acceso a la base de datos DB2, etc) se realiza mediante el uso de memoria compartida, este mecanismo presenta la ventaja de ser muy eficiente (necesaria el siglo pasado cuando los costes de computación eran muy elevados) con la contrapartida de acoplar fuertemente los procesos haciendo muy difícil su actualización o sustitución.
Esta última característica hace que la alternativa más viable para la migración progresiva de la funcionalidad desplegada en el Mainframe sea adoptar el modelo descrito por Matin Fowler como Strangler Fig.
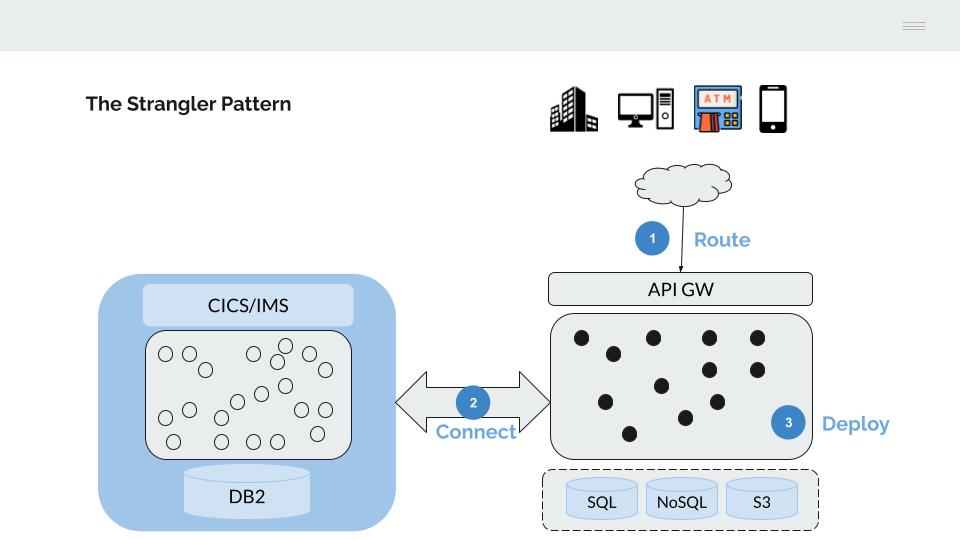
- El tráfico desde los canales, se mueve progresivamente hacia un API Gateway, que servirá para enrutar este hacia las plataformas de back-end (Mainframe o Next-gen)
- Se conectan ambas plataformas para permitir la realización de un despliegue de aplicaciones faseado
- Se migran progresivamente las aplicaciones hasta vaciar de contenido el servidor IBM mainframe
API Gateway
La conexión desde los canales se deriva de manera progresiva hacia un API Gateway.
Este API Gateway cumple dos funciones principales:
-
Por un lado, podemos entender este API Gateway como el sustituto de la funcionalidad proporcionada por el Monitor Transaccional CICS, gestionando;
- La comunicación (envío/recepción) con los canales, vamos a sustituir los códigos de transacción de 4 caracteres del CICS por APIs bien formadas
- El proceso de identificación (authentication), sustitución de CESN/CESF y RACF por un mecanismo basado en LDAP
- La autorización de operaciones, sustitución del RACF por un mecanismo basado en ACLs/RBAC
-
Por otro lado, este API Gateway nos servirá para dirigir (“Route”) el tráfico desde los canales hacia la plataforma destino, sustituyendo de manera progresiva la funcionalidad del servidor IBM mainframe por funcionalidad equivalente en la plataforma Next-gen.
Para permitir el despliegue progesivo de funcionalidad es necesario conectar ambas plataformas, estos mecanismos de conexión son esenciales para evitar la realización de despliegues “big-bang”, facilitar la marcha atrás en caso de problemas, permitir la realización de paralelos, etc, en definitiva, minimizar los riesgos inherentes a un proceso de cambio como el planteado.
Existen dos mecanismos básicos de conexión;
Proxy acceso DB2
El z/DB2 ofrece varios mecanismos de acceso mediante drivers jdbc y odbc.
De manera equivalente a la funcionalidad proporcionada por el CICS en su conexión al DB2, el proxy DB2 gestiona un pool de conexiones a la base de datos, el proceso de identificación/autorización y el cifrado del tráfico.
Proxy CICS/IMS
Permite la ejecución de transacciones mediante una conexión de bajo nivel basada en TCP/IP Sockets.
Despliegue de funcionalidad
Existen tres alternativas para la migración de la funcionalidad mainframe hacia una arquitectura Cloud.
Rebuild
La funcionalidad puede rediseñarse, escribirse en un lenguaje de programación moderno (java, python, go, …) y desplegarse como un microservicio en la plataforma Next-gen.
Estos nuevos programas pueden reutilizar la plataforma mainframe mediante la arquitectura de convivencia descrita anteriormente.
- Ejecución de sentencias SQL de acceso al DB2 a través del proxy DB2
- Invocación de una transacción mainframe mediante la llamada al proxy CICS/IMS
Refactor
En este caso, compilamos el código COBOL mainframe sobre la plataforma Next-gen (Linux-x86/arm) y lo desplegamos como un microservicio, de manera equivalente a un cualquier otro microservicio construido en java, python, go, etc.
Replace
Llamando a las APIs proporcionadas por un producto de terceros que implemente la funcionalidad requerida.
Las anteriores alternativas no son excluyentes, pueden seleccionarse diferentes alternativas para cada funcionalidad o aplicativo mainframe, sin embargo todas comparten la misma arquitectura técnica, el mismo pipeline para la construcción y despliegue y se benefician de las ventajas proporcionadas por la nueva plataforma técnica (seguridad, cifrado, automatización, etc.).
4.2 - Modelo de microservicios
¿Qué modelo de construcción de microservicios necesitamos para ejecutar programas COBOL?
El modelo de construcción de microservicios debe permitir:
- El uso de distintos lenguajes de programación (incluido COBOL)
- Que los microservicios sean interoperables (entre ellos y con la lógica del mainframe)
- La migración de datos entre plataformas (Mainframe DB2 / Next-gen SQL)
Para ello, vamos a utilizar como modelo de referencia la Hexagonal architecture.
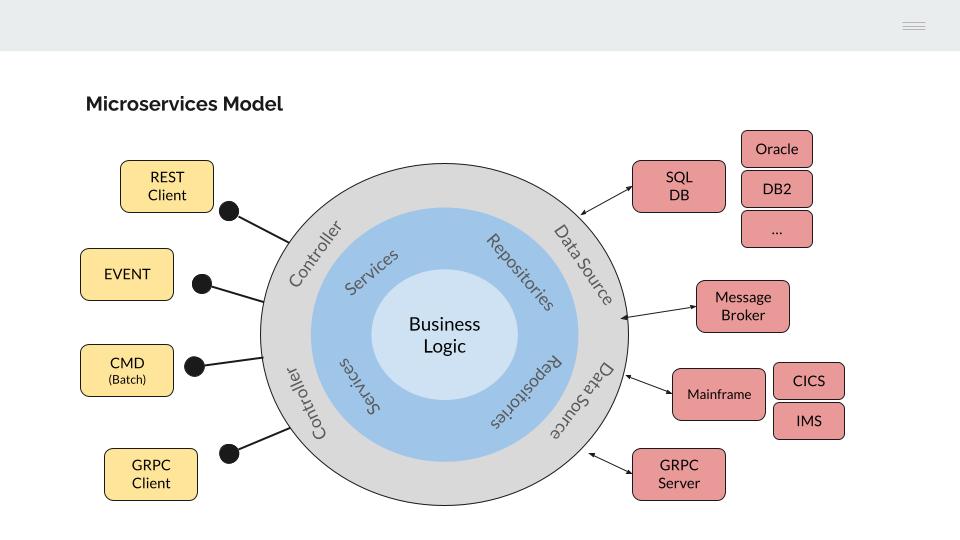
Si observamos la parte izquierda del modelo, los programas de aplicación están desacoplados de la interfaz utilizada para su ejecución. Este concepto nos debe resultar familiar ya que es equivalente al modelo utilizado en la construcción de aplicaciones COBOL en un mainframe IBM.
El lenguaje COBOL tiene sus orígenes en los años 60 del siglo pasado, cuando todo el procesamiento se realizaba en Batch. IBM desarrolla posteriormente sus monitores transaccionales CICS/IMS para permitir la conexión de los programas COBOL con dispositivos de su arquitectura de comunicaciones SNA.
Los programas COBOL manejan únicamente estructuras de datos (COBOL COPYBOOKS) y es el monitor transaccional el encargado de gestionar la interfaz de comunicación (LU0, LU2, Sockets, MQSeries, etc)
De manera equivalente, la funcionalidad de negocio implementada en los microservicios se independiza de la interfaz utilizada para su invocación, mediante un “controlador” específico.
Esto nos va a permitir la reutilización de la lógica aplicativa desde distintos interfaces, por ejemplo:
- API REST (json)
- API gRPC (proto)
- Eventos (kafka consumer)
- Consola (procesos Batch)
- Etc.
Los programas COBOL se adaptan a la perfección a este modelo, solo es necesario un proceso de conversión desde la interfaz seleccionada (json / proto) a una estructura COPYBOOK.
Atendiendo a la parte derecha del modelo, la lógica de negocio debería ser agnóstica de la infraestructura necesaria para la recuperación de los datos.
Si bien este modelo presenta evidentes ventajas, el nivel de abstracción y complejidad a introducir en el diseño y construcción de los microservicios es elevado, lo que nos lleva a hacer una implementación parcial del modelo, centrándonos en dos aspectos relevantes que aportan valor;
Bases de Datos SQL
El acceso al DB2 del mainframe se realiza a través de un proxy.
Este proxy expone una interfaz gRPC para permitir su invocación desde microservicios escritos en distintos lenguajes de programación.
Este mismo mecanismo se replica para el acceso a otros gestores de bases de datos SQL (por ejemplo, Oracle o PostgreSQL).
La migración de datos entre plataformas (por ejemplo de DB2 a Oracle) se facilita mediante la configuración en el microservicio del Data Source destino.
Invocación de transacciones CICS/IMS
En este caso, los programas CICS/IMS se exponen como microservicios (http/REST o gRPC), facilitando su posterior migración siempre que se respete la estructura de datos manejada por el programa.
4.3 - Arquitectura Online
¿Cómo migrar las transacciones CICS/IMS a microservicios?
La respuesta debería ser bastante sencilla, compilando el programa COBOL y desplegando el objeto en un contenedor (por ejemplo, Docker).
Sin embargo, existen dos tipos de sentencias en los programas Online que forman parte del lenguaje y que deben ser pre-procesadas previamente:
- Las sentencias del monitor transaccional utilizado (CICS/IMS)
- Las sentencias de acceso a la base de datos DB2
Sentencias CICS
Los programas Online se despliegan en un monitor transaccional (CICS/IMS), este realiza una serie de funciones que no pueden realizarse utilizando directamente el lenguaje de programación COBOL.
La principal función sería el envío/recepción de mensajes.
El lenguaje COBOL tiene sus orígenes a mediados del SXX, cuando todo el procesamiento se realizaba en batch, no existían dispositivos con los que conectarse
El monitor transaccional es por tanto el encargado de gestionar la comunicación. Los programas COBOL definen una estructura de datos fija (COPYBOOK) e incluyen como parte de su código sentencias CICS (EXEC CICS SEND/RECEIVE) para el envío o recepción de mensajes de aplicación.
El monitor transaccional utilizará la dirección (puntero) y longitud de la COPYBOOK para leer/escribir sobre ella el mensaje
El modelo de microservicios propuesto se comporta de manera equivalente al CICS/IMS, extendiendo las capacidades del gRPC/proto al lenguaje COBOL.
-
Las COPYBOOK del programa COBOL (datos en LINKAGE SECTION) utilizadas para enviar/recibir mensajes se transforman en mensajes proto
-
Un controlador especializado se encarga de gestionar la interfaz gRPC (gRPC server)
-
El mensaje se convierte de formato proto a COPYBOOK. Se transforman los datos del mensaje (string, int, float, etc.) a datos COBOL (CHAR, DECIMAL, PACKED DECIMAL, etc.)
-
Finalmente se usa Go cgo para cargar el programa COBOL y ejecutarlo pasándole la estructura de datos generada
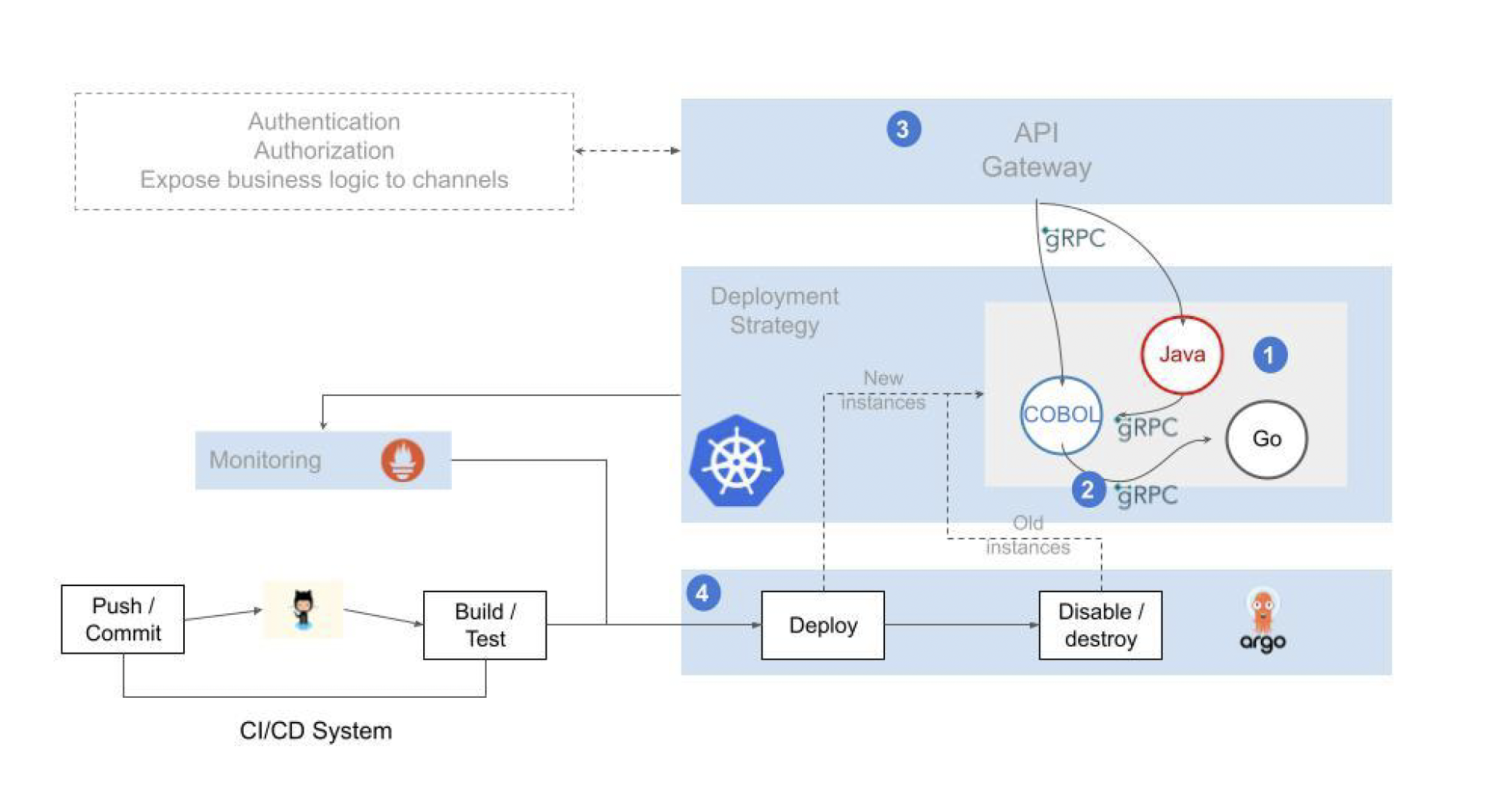
-
La solución permite la codificación de servicios en lenguajes modernos y atractivos para los desarrolladores. A su vez permite el aprovechamiento de piezas codificadas en lenguajes “legacy” cuya recodificación resultaría en un gasto de recursos innecesario
-
La comunicación entre los diferentes servicios, comunicación interna, se implementa mediante un protocolo ligero y eficiente
-
Los servicios son invocados desde frontales o sistemas de terceros (plataformas de pagos de terceros, software de partners u otras entidades, etc.) a través de un mecanismo de exposición securizado, resiliente y fácilmente escalable
-
La operación está soportada por pipelines para la automatización de los despliegues y capacidades avanzadas de observabilidad que permiten una visión integrada y consistente de todo el flujo aplicativo y del estado de salud de los elementos involucrados
El resto de sentencias CICS comunes en los programas de aplicación (ASKTIME/FORMATTIME, LINK, READQ TS, WRITEQ TS, RETURN, etc) pueden sustituirse directamente por código COBOL (ASKTIME, RETURN, LINK) o por llamadas a utilidades desarrolladas en Go cgo.
Sentencias DB2
Las sentencias de acceso a la base de datos DB2 son de tipo estático.
Estas deben pre-compilarse, existiendo dos opciones:
-
Utilizar el pre-procesador proporcionado por el fabricante de la base de datos (por ejemplo, Oracle Pro*COBOL)
-
Pre-procesar las sentencias DB2 (EXEC SQL) para utilizar el Proxy de acceso a base de datos SQL proporcionado por la arquitectura de convivencia
4.4 - Arquitectura Batch
¿Cómo ejecutar procesos Batch en una arquitectura open?
A continuación se describen los principales componentes de la arquitectura Batch de IBM, es importante entender las capacidades de cada uno de ellos para replicarlas sobre una arquitectura open basada en contenedores.
- JCL
- JES
- Programas de aplicación (COBOL, PL/I, etc.)
- Datos (Ficheros y Bases de Datos.)
JCL
Podemos pensar en un JCL como un antepasado lejano de un DAG (Directed Acrylic Graph), es un conjunto de sentencias, heredadas de la tecnología de las fichas perforadas, que definen el proceso y la secuencia de pasos a ejecutar.
En el JCL vamos a encontrar las características básicas del proceso o job (nombre, tipo, prioridad, recursos asignados, etc.), la secuencia de programas a ejecutar, las fuentes de información de entrada y qué hacer con los datos de salida del proceso.
Las principales sentencias que encontraremos en un JCL son las siguientes;
- Una ficha JOB, donde se define el nombre del proceso y sus características
- Una o varias fichas EXEC con cada programa que debe ser ejecutado
- Una o varias fichas DD, con la definición de los ficheros (Data Sets) utilizados por los programas anteriores
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=PROGRAM1
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
JES
El JES es el componente (subsistema) del Z/OS que se encarga de procesar el Batch. Realiza dos tareas principales:
- La planificación (scheduling) de los procesos Batch
- Asignación del proceso a una clase o iniciador (los jobs pueden asignarse a colas específicas)
- Definir la prioridad del proceso
- Asignar/limitar los recursos asignados al proceso (memoria, tiempo, etc.)
- Controlar el flujo de ejecución de los pasos (STEPs) del proceso
- La ejecución de los programas
- Validación de las sentencias del JCL
- Cargar los programas (COBOL, PL/I) en memoria para su posterior ejecución
- Asignación de los ficheros de entrada/salida a los nombres simbólicos definidos en los programas de aplicación COBOL PL/I
- Logging
Programas de aplicación
Programas, generalmente codificados usando COBOL, que implementan la funcionalidad del proceso.
El ejecutable resultado de la compilación del código fuente se almacena como un miembro de una librería particionada (PDS). Las librerías desde donde cargar los programas se identifican mediante una ficha específica en el JCL (JOBLIB / STEPLIB).
El JES invocará al programa principal del proceso (definido en la ficha EXEC del JCL) y este a su vez podrá llamar a distintas subrutinas de manera estática o dinámica.
Datos
El acceso a los datos se realiza principalmente mediante la utilización de ficheros (Data Sets) y Bases de Datos relacionales (DB2).
Los ficheros de entrada/salida se definen en los programas con un nombre simbólico.
SELECT LOAN ASSIGN TO "INPUT1"
ORGANIZATION IS LINE SEQUENTIAL
ACCESS IS SEQUENTIAL.
La asignación de los nombres simbólicos a ficheros de lectura/escritura se realiza en el JCL, mediante la ficha DD.
//*
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
Los ficheros generalmente son de tipo;
- Secuencial, los registros deben ser accedidos de manera secuencial, es decir, para leer el registro 1.000 previamente han leerse los anteriores 999 registros
- VSAM. Existen distintos tipos de ficheros VSAM, siendo posible acceder a los registros directamente mediante mediante una clave (KSDS) o número de registro (RRDS)
En el caso de que el programa necesite acceder a una Base de Datos (DB2), la información necesaria para la conexión (seguridad, nombre de la Base de Datos, etc.) se pasa como parámetros en el JCL.
Migración del Batch mainframe a una arquitectura open
Para la migración de los procesos Batch construidos sobre tecnología mainframe vamos a replicar la funcionalidad descrita anteriormente sobre un clúster Kubernetes.
Es necesario por tanto;
- Convertir los JCLs (JOBs) a una herramienta o framework que permita la ejecución de workflows sobre una plataforma Kubernetes
- Replicar las funcionalidad del JES para permitir el scheduling y ejecución de los programas COBOL PL/I sobre el cluster Kubernetes
- Recompilar los programas de aplicación
- Permitir el acceso a los datos (ficheros y Bases de Datos)
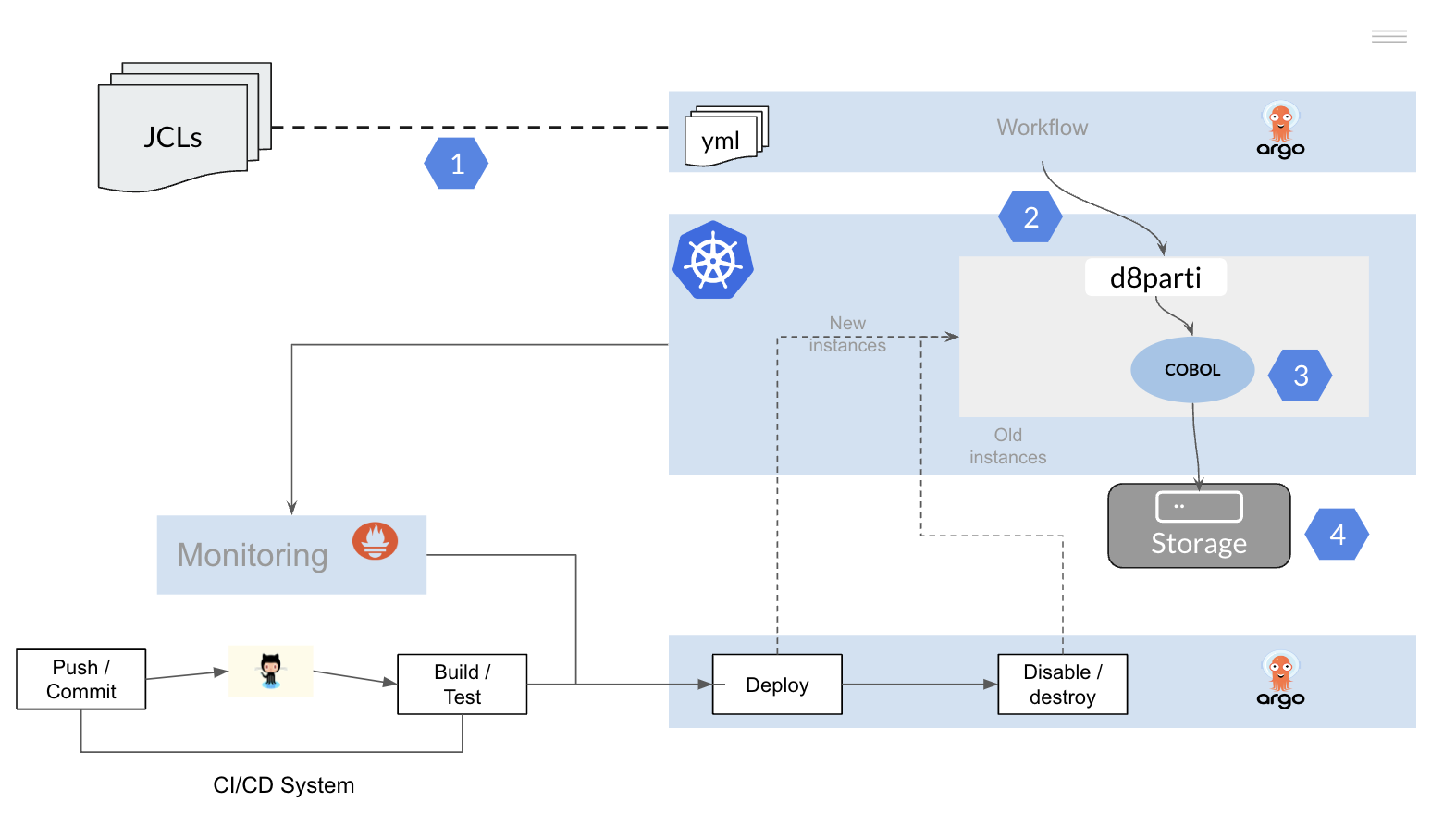
4.4.1 - Conversión JCLs
¿Cómo convertir un JCL mainframe en un DAG?
A continuación se muestra un sencillo ejemplo de cómo convertir un JCL a un workflow de Argo (yaml).
Pueden utilizarse otros frameworks o herramientas que permitan la definición de DAGs y tengan una integración nativa con la plataforma Kubernetes.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: batch-job-example
spec:
entrypoint: job
templates:
- name: job
dag:
tasks:
- name: extracting-data-from-table-a
template: extractor
arguments:
- name: extracting-data-from-table-b
template: extractor
arguments:
- name: extracting-data-from-table-c
template: extractor
arguments:
- name: program-transforming-table-c
dependencies: [extracting-data-from-table-c]
template: exec
arguments:
- name: program-aggregating-data
dependencies:
[
extracting-data-from-table-a,
extracting-data-from-table-b,
program-transforming-table-c,
]
template: exec
arguments:
- name: loading-data-into-table1
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: loading-data-into-table2
dependencies: [program-aggregating-data]
template: loader
arguments:
- name: extractor
- name: exec
- name: loader
Proceso Batch de ETL dividido en tres fases:
- La extracción de información desde un conjunto de tablas DB2 (template extractor)
- La transformación y agregación de las mismas mediante programas de aplicación COBOL (template exec)
- La carga de la información resultante (template loader)
Cada JOB se transforma en un DAG en el que se define la secuencia de pasos (STEPs) a ejecutar y sus dependencias
Es posible definir “templates” con los principales tipos de tareas Batch de la instalación (descarga datos DB2, ejecución de programas COBOL, transmisión de ficheros, conversión de datos, etc.) de manera equivalente a los PROCS en mainframe
Cada STEP dentro del DAG es ejecutado en un contenedor independiente en un cluster Kubernetes
Las dependencias se definen a nivel de tarea en el DAG, pudiendo establecer árboles de ejecución no lineales
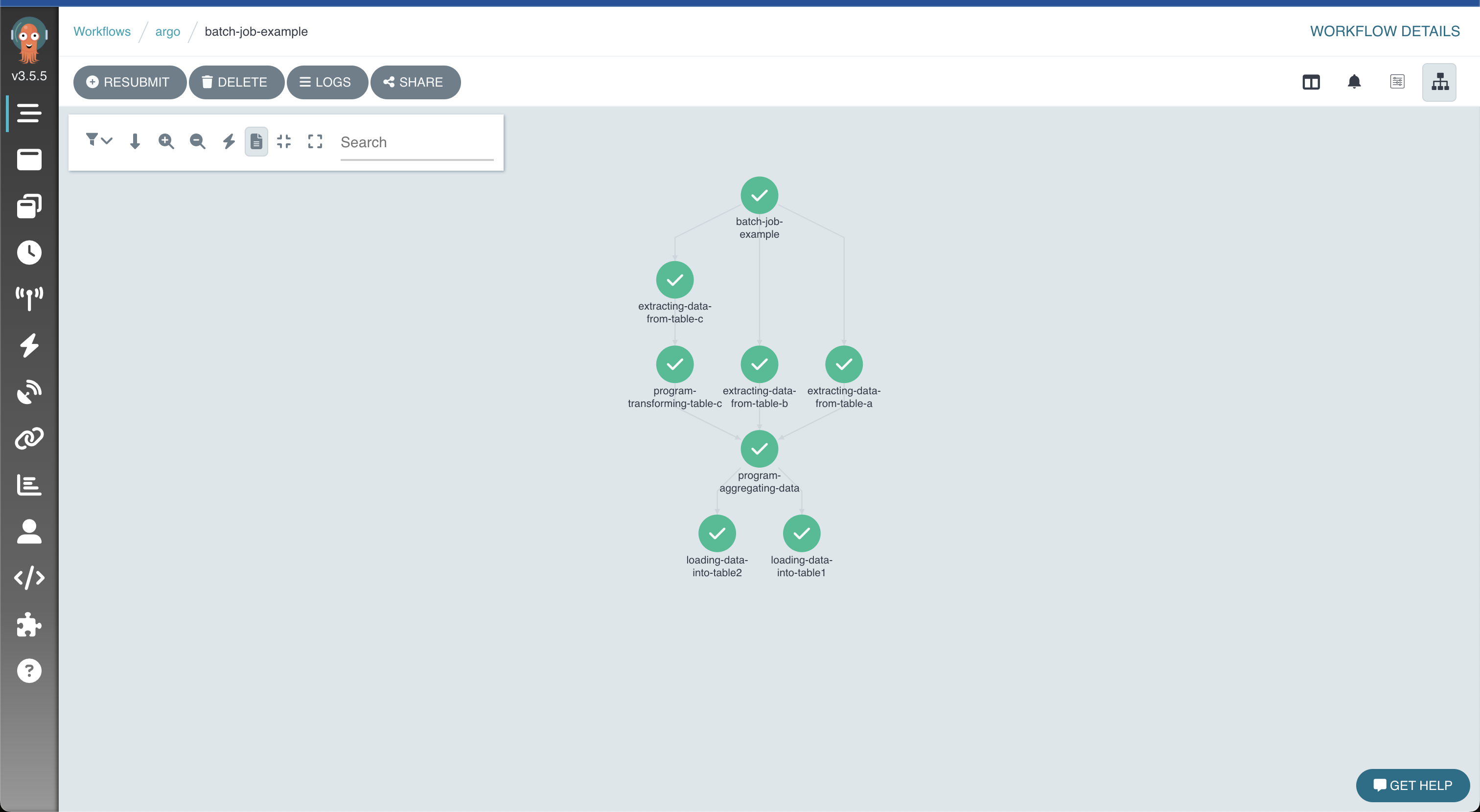
Resultado de la ejecución del proceso representado de manera gráfica en Argo
4.4.2 - Replicar JES
¿Cómo replicar la funcionalidad del JES?
Si está familiarizado con The Twelve-Factor App, conocerá que uno de sus principios pasa por independizar el código de aplicación de cualquier elemento que pueda variar en el despliegue del mismo en distintos entornos (pruebas, calidad, producción, etc).
Guardar la configuración en el entorno
La configuración de una aplicación es todo lo que puede variar entre despliegues (entornos de preproducción, producción, desarrollo, etc)
The Twelve-Factor App. III Configuraciones
Podemos asimilar la información contenida en los JCLs a ficheros de configuración (config.yml) que contendrán la información necesaria para la ejecución del código en cada uno de los entornos definidos en la instalación (recursos asignados, conexión a la base de datos, nombre y localización de los ficheros de entrada/salida, nivel de detalle del log, etc).
Para entender qué funcionalidad debemos replicar vamos a dividir un JCLs en dos partes:
- Ficha JOB
- Ficha EXEC y DD
//JOB1 JOB (123),CLASS=C,MSGCLASS=S,MSGLEVEL=(1,1),NOTIFY=&SYSUID
//*
//STEP01 EXEC PGM=BCUOTA
//INPUT1 DD DSN=DEV.APPL1.SAMPLE,DISP=SHR
//OUTPUT1 DD DSN=DEV.APPL1.CUOTA,
// DISP=(NEW,CATLG,DELETE),VOLUME=SER=SHARED,
// SPACE=(CYL,(1,1),RLSE),UNIT=SYSDA,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=800)
//*
Ficha JOB
En la ficha JOB, vamos a encontrar la información básica para el “scheduling” del proceso en Kubernetes:
- Información para la clasificación del JOB (CLASS). Permite separar los tipos de JOBs en función de sus características y asignarles parámetros de ejecución distintos
- Definir la salida por defecto (MSGCLASS)
- El nivel de información que se enviará a la salida (MSGLEVEL)
- Cantidad de memoria máxima asignada al proceso (REGION)
- Tiempo máximo estimado para la ejecución del proceso (TIME)
- Información de usuario (USER)
- Etc.
En Kubernetes, el componente kube-scheduler será el encargado de realizar estas tareas, buscando un nodo con las características adecuadas para la ejecución de los pods recién creados. Existen distintas opciones;
- Los procesos Batch pueden usar el Job controller de Kubernetes, este ejecutara un pod por cada paso (STEP) del workflow y lo detendrá una vez finalizada la tarea
- En caso de necesitar funcionalidad más avanzada, por ejemplo para la definición y priorización de distintas colas de ejecución, pueden utilizarse “schedulers” especializados como Volcano
- Por último, es posible desarrollar un controlador kubernetes que se adapte a las necesidades específicas de una instalación
Ficha EXEC y DD
En cada paso (STEP) del JCL podemos encontrar una ficha EXEC y varias fichas DD.
En estas se define el programa (COBOL) a ejecutar y los ficheros de entrada/salida asociados.
A continuación se muestra un ejemplo de cómo transformar un paso (STEP) de un JCL.
---
stepname: "step01"
exec:
pgm: "bcuota"
dd:
- name: "input1"
dsn: "dev/appl1/sample.txt"
disp: "shr"
normaldisp: "catlg"
abnormaldisp: "catlg"
- name: "output1"
dsn: "dev/appl1/cuota.txt"
disp: "new"
normaldisp: "catlg"
abnormaldisp: "delete"
Para la ejecución de programas, las sentencias EXEC y DD se convierten a YAML. Esta información se pasa al controlador d8parti, especializado en la ejecución de programas Batch.
El controlador d8parti actúa como el JES:
- Se encarga de validar la sintaxis del fichero YAML
- Asigna los nombres simbólicos en los programas COBOL a ficheros físicos de entrada/salida
- Carga el programa COBOL en memoria para su ejecución
- Escribe información de monitorización/logging
4.4.3 - Compilación programas
¿Cómo reutilizar los programas de aplicación del mainframe?
Los programas COBOL PL/I de la plataforma mainframe son directamente reutilizables sobre la plataforma técnica de destino (Linux).
Como hemos comentado anteriormente, el módulo d8parti será el encargado de:
- Inicializar el “runtime” del lenguaje (i.e. COBOL)
- Asignar los ficheros de entrada/salida a los nombres simbólicos del programa
- Cargar y ejecutar el programa principal (definido en la ficha EXEC del JCL)
Este programa principal puede realizar distintas llamadas a otras subrutinas mediante una sentencia CALL, estas llamadas son gestionadas por el “runtime” del lenguaje utilizado
Podemos visualizar este funcionamiento como un árbol invertido
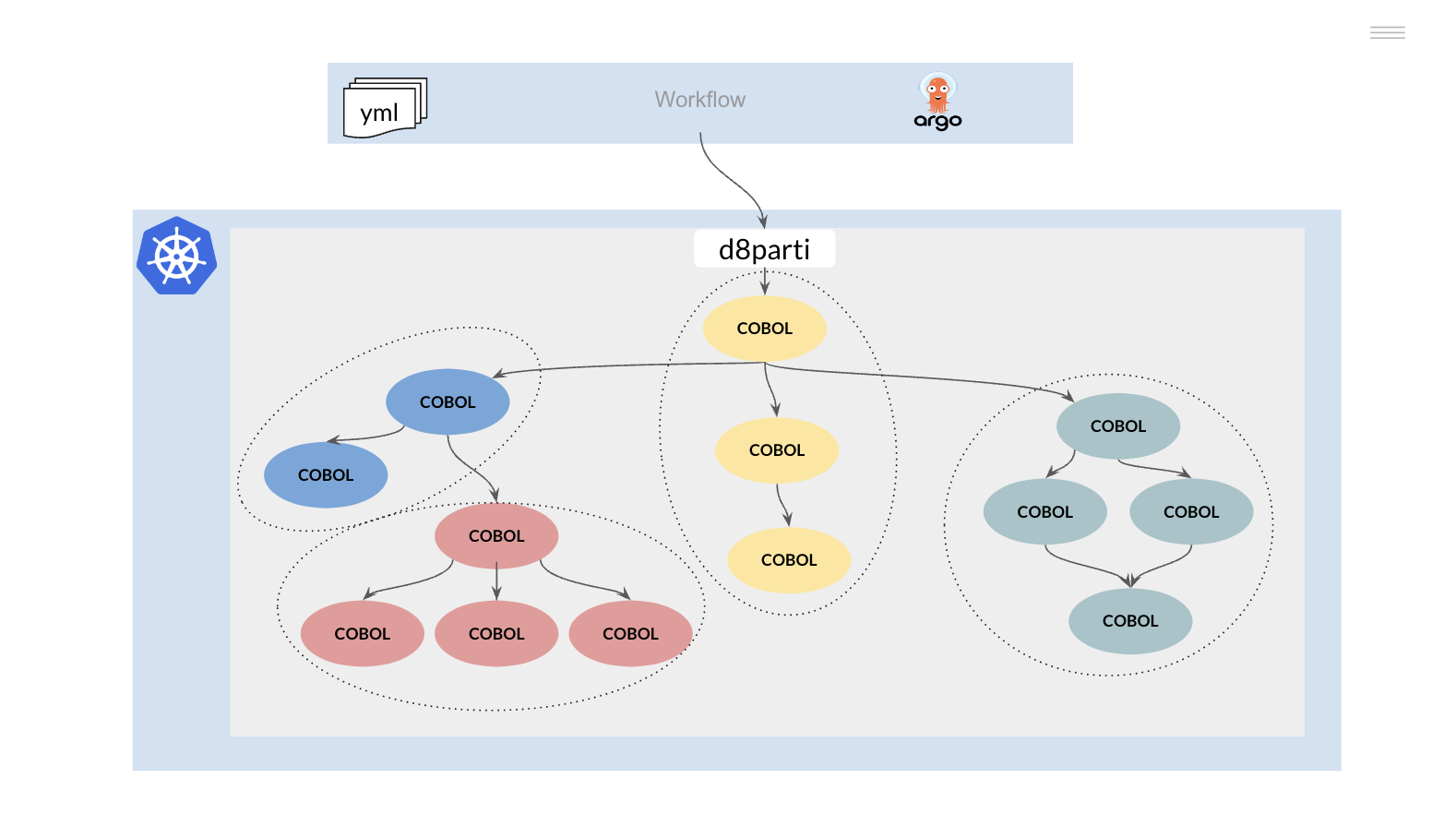
Los programas compilados pueden almacenarse en un directorio compartido y cargarse en tiempo de ejecución (CALL dinámico) replicando el funcionamiento del mainframe IBM (STEPLIB).
Sin embargo, existe la posibilidad de cambiar el comportamiento anterior e implementar un modelo de contenedores inmutables, que presenta ciertas ventajas respecto al modelo anterior. En este caso, el árbol de ejecución anterior debería descomponerse funcionalmente en uno o varios “repos”.
Las modificaciones en alguno de los componentes de estos “repos” generan una nueva versión del mismo y la consiguiente regeneración del contenedor o contenedores que lo utilicen.
Con esta estrategia conseguimos:
- Facilitar el proceso de desarrollo y prueba de las aplicaciones
- Permitir la introducción progresiva de cambios en el sistema, eliminando riesgos
- Posibilitar la portabilidad de los procesos a distintas plataformas (On-prem, On-cloud)
Una vez aislada una función de negocio en un contenedor con una interfaz estándar, este puede modificarse o re-escribirse en cualquier otro lenguaje de programación y desplegarse de manera transparente sin afectar al resto del sistema.
4.4.4 - Acceso a los datos
¿Cómo acceder a los datos almacenados en ficheros y bases de datos SQL?
Ficheros
En la arquitectura mainframe un Data Set es un conjunto de registros relacionados que se almacenan en una UNIT / VOLUME.
Para entender estos conceptos hay que volver a retroceder en el tiempo, cuando los dispositivos de almacenamiento masivo estaban basados en cintas o cartuchos. Así, cuando un proceso necesitaba acceder a la información de un Data Set, la cinta o cartucho tenía que ser “montada” en una UNIT y era identificado con un nombre o VOLUME.
Hoy en día la información reside en disco y no necesita ser montada/desmontada para su acceso, podemos asimilar los VOLUMEs del mainframe a un “share” de un NFS.
Pueden definirse distintos “puntos de montaje” al contenedor aplicativo para aislar la información y proteger su acceso (por ejemplo por entorno, desarrollo y producción). El acceso se ofrece a los contenedores mediante SDS (Software Define Storage) con el objetivo de poder desacoplar el almacenamiento del proceso.
Por último, los ficheros del mainframe deben transmitirse y convertirse (EBCDIC) a ficheros “Linux” para su utilización en la plataforma destino. Este proceso puede automatizarse mediante herramientas/productos de mercado o usando procesos Spark de conversión de datos.
Base de Datos
El principal motor de Base de Datos del mainframe es el IBM DB2, aunque se siguen utilizando de manera residual otro tipo de productos (IMS DB, IDMS, Adabas).
En el caso de las aplicaciones DB2. Existen dos grandes estrategias bien diferenciadas para el acceso a los datos:
- Réplica de los datos DB2 sobre una nueva Base de Datos SQL (por ejemplo, PostgreSQL)
- Acceso al DB2 de la plataforma mainframe desde el cluster Kubernetes mediante el proxy de convivencia
En el primer caso, los datos de las tablas DB2 se replican sobre un nuevo gestor usando herramientas de replicación (i.e. IBM CDC) o procesos ETL (por ejemplo usando Spark).
Las sentencias SQL DB2 (EXEC SQL … END-EXEC.) se pre-compilan para poder acceder al nuevo gestor de base de datos, es necesario realizar pequeños cambios en el SQL para adaptarlo, sin embargo existe metodología y herramientas para la realización de este proceso de manera automática:
- Réplica del DDL (Tablespaces, Tablas, Índices, Columnas, etc.)
- Adaptación tipos de datos DATE/TIME
- SQLCODEs
- Utilidades de carga y descarga
- Etc
El principal inconveniente de esta estrategia es la necesidad de mantener la integridad de datos del modelo, generalmente el modelo de integridad referencial de la base de datos no está definido en el gestor DB2, debe deducirse por la lógica de las aplicaciones.
Todos los procesos de lectura/actualización que accedan a las tablas afectadas (independientemente de si son Batch/Online) deben ser migrados a la nueva plataforma o definir un mecanismo de convivencia/réplica entre plataformas (Mainframe DB2 / Next-gen SQL) que mantenga la integridad de los datos en ambas hasta la finalización del proceso de migración.
Esta convivencia se hace especialmente crítica en el caso de tablas con datos maestros accedidos por un elevado número de aplicaciones.
En caso de optar por seguir accediendo al DB2 mainframe mediante el proxy de convivencia no es necesario mantener la integridad de los datos entre plataformas (Mainframe / Next-gen). Los procesos (Online o Batch) se pueden migrar individualmente y de manera progresiva (canary deployment)
Una vez finalizado el proceso de migración de los programas de aplicación (Online y Batch) puede realizarse una migración de datos hacia una nueva Base de Datos en la plataforma destino (Next-gen).
5.1 - Variables en el lenguaje COBOL
¿Cómo convertir una COPYBOOK COBOL a una estructura en Go?
Variables en el lenguaje COBOL
Cualquier programa COBOL puede ser transformado en un microservicio y desplegado en Kubernetes.
Para ello, simplemente debe compilarse el programa y generar un módulo ejecutable que pueda ser invocado de manera dinámica o estática desde otro programa de aplicación. Puede consultar los ejemplos para aprender a realizar llamadas tanto dinámicas como estáticas.
De manera análoga al comportamiento de una función en un lenguaje de programación moderno, estos programas o subrutinas pueden recibir un conjunto de variables como parámetros de entrada/salida.
El procedimiento es sencillo, se debe codificar la cláusula USING en la PROCEDURE DIVISION replicado el número, orden y tipo de las variables utilizadas en la llamada realizada desde el programa principal.
En el caso de los programas Batch, el programa principal (asociado a una ficha STEP de un JCL) no suele utilizar parámetros (PARM) para la recepción de datos de entrada al programa. Los programas generalmente utilizan la sentencia COBOL ACCEPT o leen la información necesaria directamente desde un fichero.
En el caso de los programas Online, el programa principal se asocia a una transacción y es el gestor transaccional (CICS o IMS) el encargado de invocar dicho programa. Este programa suele utilizar las sentencias correspondientes del gestor transaccional para recibir un mensaje compuesto por diferentes variables (EXEC CICS RECEIVE - GN) sobre un área de memoria previamente definida.
Independientemente del modo de ejecución (Online o Batch), estos programas COBOL principales pueden a su vez realizar distintas llamadas a subrutinas COBOL mediante la sentencia CALL (en el caso de utilizar CICS esa llamada podría realizarse mediante la sentencia EXEC CICS LINK).
Por tanto, si queremos exponer un programa COBOL como un microservicio que pueda ser invocado desde otros microservicios escritos en distintos lenguajes de programación es necesario entender los distintos tipos de datos que puede utilizar un programa COBOL y convertirlos a un tipo estándar utilizable desde cualquier lenguaje de programación.
Tipos de variables en COBOL
Definir una variable en un programa COBOL puede resultar confuso para alguien acostumbrado a trabajar con lenguajes de programación actuales. Adicionalmente, existen distintos tipos de datos, ampliamente utilizados por un programador COBOL, que no tienen equivalencia en cualquier lenguaje de programación moderno.
Vamos a intentar descifrar el funcionamiento de los tipos de datos COBOL más utilizados en un programa estándar y a definir su traducción a un lenguaje moderno como Go.
Se excluyen variables que requieren caracteres de doble byte
Como en cualquier otro lenguaje, para definir una variable, debemos declarar su nombre y su tipo (string, int, float, bytes, etc.), sin embargo en COBOL esa definición no es directa, se realiza mediante las cláusulas USAGE y PICTURE.
01 VAR1 PIC S9(3)V9(2) COMP VALUE ZEROES.
Mediante la cláusula USAGE definiremos el tipo de almacenamiento interno que utilizará la variable.
La cláusula PICTURE (o PIC) define la máscara asociada a la variable y sus características generales, esta definición se realiza mediante la utilización de un conjunto de caracteres o símbolos específicos:
- A, la variable contiene caracteres alfabéticos
- X, la variable contiene caracteres alfanuméricos
- 9, variable numérica
- S, indica una variable numérica con signo
- V, número de posiciones decimales en una variable numérica
- Etc.
USAGE DISPLAY
Las variables definidas como USAGE DISPLAY puede ser de los siguientes tipos:
Alfabéticas
Se definen mediante la utilización del símbolo A en la cláusula PICTURE.
01 VAR-ALPHA PIC A(20).
Sólo pueden almacenar caracteres del alfabeto latino. Su uso no es muy común, siendo generalmente sustituidas por variables alfanuméricas que veremos a continuación.
Alfanuméricas
Se definen mediante la utilización del símbolo X en la cláusula PICTURE.
01 VAR-CHAR PIC X(20).
Como en el anterior caso no es necesario definir la cláusula USAGE, ya que las variables de tipo A o X por defecto son de tipo DISPLAY.
Numéricas
Se definen mediante la utilización del símbolo 9 en la cláusula PICTURE.
01 VAR1 PIC S9(3)V9(2) USAGE DISPLAY.
En este caso estamos definiendo una variable numérica de longitud 5 (3 posiciones enteras y 2 decimales) con signo.
La definición de variables numéricas de tipo DISPLAY puede hacerse de manera explícita como en el ejemplo anterior o de manera implícita en caso de no codificar la cláusula USAGE.
Almacenamiento interno
Cada uno de los caracteres definidos se almacena en un byte (EBCDIC), en el caso de variables de tipo numérico con signo, este se define en los primeros 4 bits del último byte.
Vamos a ver un ejemplo para entender mejor el funcionamiento de este tipo de variables.
| Número |
Valor EBCDIC |
| 0 |
x’F0' |
| 1 |
x’F1' |
| 2 |
x’F2' |
| 3 |
x’F3' |
| 4 |
x’F4' |
| 5 |
x’F5' |
| 6 |
x’F6' |
| 7 |
x’F7' |
| 8 |
x’F8' |
| 9 |
x’F9' |
Si le asignamos un valor de 12345 a una variable de tipo
PIC 9(5) USAGE DISPLAY
Está ocuparía 5 bytes
12345 = x’F1F2F3F4F5’
En el caso de variables con signo
PIC S9(5) USAGE DISPLAY
+12345 = x’F1F2F3F4C5’
-12345 = x’F1F2F3F4D5’
USAGE COMP-1 o COMPUTATIONAL-1
Variable de tipo float de 32 bits (4 bytes).
USAGE COMP-2 o COMPUTATIONAL-2
Variable de tipo float de 64 bits (8 bytes).
Tanto en el caso de variables tipo COMP-1 como tipo COMP-2, no se puede definir una cláusula PICTURE asociada a dicha variable.
USAGE COMP-3 o COMPUTATIONAL-3
Variable numérica de tipo Packed-Decimal.
01 VAR-PACKED PIC S9(3)V9(2) USAGE COMP-3.
Se utilizan 4 bits para almacenar cada uno de los caracteres numéricos de la variable, el signo se almacena en los últimos 4 bits.
Por lo general, este tipo de variables se definen de longitud impar, para ocupar por completo el número de bytes utilizados.
Una sencilla regla para calcular el almacenamiento ocupado por una variable tipo COMP-3 es dividir la longitud total de la variable (posiciones enteras + posiciones decimales) entre 2 y sumarle 1, en el ejemplo anterior el almacenamiento requerido para la variable VAR-PACKED
5 / 2 = 2 -> longitud total 5 (3 enteros + 2 decimales)
2 + 1 = 3 -> almacenamiento requerido 3 bytes
Vamos a ver un ejemplo para comprender mejor el funcionamiento de este tipo de variables.
Vamos a asignarle el valor 12345, como en el ejemplo anterior, a una variable de tipo COMP-3.
PIC S9(5) USAGE COMP-3.
Partimos del número en formato DISPLAY
x’F1F2F3F4F5’
Eliminamos los primeros 4 bits de cada byte y añadimos el signo al final
+12345 = x’12345C’
-12345 = x’12345D’
USAGE COMP-4 o COMPUTATIONAL-4 o COMP o BINARY
En este caso, el tipo de dato es numérico binario. Los números negativos se representan como complemento a 2.
El tamaño del almacenamiento requerido depende de la cláusula PICTURE.
| PICTURE |
Almacenamiento |
Valor |
| PIC S9(1) - S9(4) |
2 bytes |
-32,768 hasta +32,767 |
| PIC S9(5) - S9(9) |
4 bytes |
-2,147,483,648 hasta +2,147,483,647 |
| PIC S9(10) - S9(18) |
8 bytes |
-9,223,372,036,854,775,808 hasta +9,223,372,036,854,775,807 |
| PIC 9(1) - 9(4) |
2 bytes |
0 hasta 65,535 |
| PIC 9(5) - 9(9) |
4 bytes |
0 hasta 4,294,967,295 |
| PIC 9(10) - 9(18) |
8 bytes |
0 hasta 18,446,744,073,709,551,615 |
Hasta aquí el funcionamiento de este tipo de variables sería equivalente a la representación de variables enteras en la mayoría de lenguajes de programación (variables short, long o double y sus equivalentes sin signo ushort, ulong, udouble), sin embargo mediante el uso de la cláusula PICTURE podemos limitar los valores máximos de dicha variable y definir una máscara decimal.
Por ejemplo:
01 VAR-COMP PIC 9(4)V9(2) USAGE COMP.
Utiliza 4 bytes de almacenamiento (int32), pero su valor está limitado desde 0 a 9999.99.
¿Qué sentido tiene definir variables enteras y posteriormente definir una máscara fija con el número de posiciones enteras y decimales?
Limitar el uso de operaciones con coma flotante. Hoy en día esto puede resultar extraño, pero tenía sentido hace 30 años para reducir los ciclos de CPU utilizados cuando el coste de computación era extremadamente caro.
Por otro lado, la práctica totalidad de las operaciones realizadas por instituciones financieras con moneda no requieren cálculos complejos y al operar con números enteros no perdemos precisión en caso de necesitar posiciones decimales (i.e. céntimos).
USAGE COMP-5 o COMPUTATIONAL-5
Este tipo de dato también es conocido como binario nativo.
Es equivalente a COMP-4, sin embargo los valores a almacenar no están limitados por la máscara definida en la cláusula PICTURE.
| PICTURE |
Almacenamiento |
| PIC S9(4) COMP-5 |
short (int16) |
| PIC S9(9) COMP-5 |
long (int32) |
| PIC S9(18) COMP-5 |
double (int64) |
| PIC 9(4) COMP-5 |
ushort (uint16) |
| PIC 9(9) COMP-5 |
ulong (uint32) |
| PIC 9(18) COMP-5 |
udouble (uint64) |
Conversión de variables a un tipo estándar
Es importante comentar que solo es necesario convertir las variables expuestas por los programas principales, una vez inicializado el runtime de cobol utilizado y ejecutado el programa principal, las llamadas entre programas COBOL realizadas mediante la sentencia CALL son responsabilidad del runtime.
Un caso especial es la llamada entre programas COBOL, desplegados en distintos contenedores. Para ello se ha diseñado un mecanismo específico, similar al funcionamiento de la sentencia LINK del gestor transaccional CICS.
Puede consultar cómo realizar llamadas entre programas COBOL desplegados en distintos contenedores aplicativos en el apartado de ejemplos d8link.
Como norma general, cualquier variable COBOL podría ser expuesta de distintas formas (int, float, string, etc.) y ser convertida posteriormente, sin embargo y para simplificar y optimizar el proceso de conversión vamos a utilizar un conjunto de reglas sencillas que describiremos a continuación.
EBCDIC
Como hemos comentado anteriormente, el mainframe IBM utiliza EBCDIC internamente.
Para intentar replicar al máximo el comportamiento de los programas COBOL entre plataformas, algunos fabricantes permiten seguir utilizando EBCDIC internamente para el manejo de datos de aplicación.
Si bien, a corto plazo esta estrategia podría facilitar la migración del código, presenta enormes problemas de compatibilidad, evolución y soporte a medio largo plazo. Por tanto, los programas COBOL migrados utilizarán caracteres ASCII internamente.
Es necesario identificar los programas que hagan uso de instrucciones COBOL que manejan caracteres hexadecimales y reemplazar dichas cadenas de caracteres
MOVE X’F1F2F3F4F5’ TO VAR-NUM1.
Big-endian vs little-endian
La plataforma mainframe IBM es big-endian, el byte más significativo estaría almacenado en la dirección de memoria de menor valor, o dicho de otro modo el signo se almacenaría en el primer bit de la izquierda.
Por el contrario la plataforma x86 y arm utilizan little-endian para la representación de variables binarias.
Como en el caso anterior, pensamos que la mejor estrategia es utilizar de manera nativa la arquitectura de destino, por tanto los programas serán compilados para utilizar little-endian.
Tamaño máximo variables COMP
Como regla general, el tamaño máximo de una variable numérica es 18 posiciones, independientemente del tipo utilizado (DISPLAY, COMP, COMP-3, COMP-5).
Existe sin embargo, la capacidad en la plataforma mainframe de extender ese límite hasta 31 dígitos en el caso de algún tipo de variable (por ejemplo COMP-3).
Estamos hablando de variables numéricas utilizadas para realizar operaciones aritméticas, salvo en el caso concreto de algún país con episodios de hiperinflación mantenidos durante un largo periodo de tiempo, el límite de 18 dígitos es suficiente.
Variables binarias
Aunque no es habitual utilizar variables de tipo binario con máscara decimal (COMP o COMP-4), pueden utilizarse para operar en binario números de gran tamaño o precisión y evitar así el uso de campos tipo float.
En el caso de variables de tipo COMP-5 o binarias nativas, no tiene sentido aplicar una máscara decimal, por tanto su implementación será directa a un tipo de variable entera correspondiente a su tamaño.
Modelo de conversión
| Tipo COBOL |
Tipo Go |
| PIC X(n) |
string |
| COMP-1 |
float32 |
| COMP-2 |
float64 |
| PIC S9(1 hasta 4) COMP-5 |
int16 |
| PIC S9(5 hasta 9) COMP-5 |
int32 |
| PIC S9(10 hasta 18) COMP-5 |
int64 |
| PIC 9(1 hasta 4) COMP-5 |
uint16 |
| PIC 9(5 hasta 9) COMP-5 |
uint32 |
| PIC 9(10 hasta 18) COMP-5 |
uint64 |
En COBOL no existe el concepto de String, el tamaño de la variable PIC X(n) corresponde siempre y exactamente a la longitud definida en la cláusula PIC.
En caso de que el tamaño del string sea menor al tamaño definido en COBOL, será necesario justificar con espacios por la derecha.
Hasta aquí las variables que presentan una equivalencia con algún tipo de variable del lenguaje Go, a continuación vamos a definir el comportamiento de los tipos de datos numéricos con máscara decimal.
Estos son los tipos de datos generalmente utilizados por los programadores COBOL. En el caso de que el programa quiera ser expuesto para su invocación desde una plataforma externa, suelen utilizarse variables de tipo DISPLAY o zoned decimal para facilitar la conversión de datos (ASCII-EBCDIC) entre plataformas y facilitar la depuración de errores.
En nuestro caso, para simplificar el manejo de datos, todas estas variables se expondrán como tipo string.
| Tipo COBOL |
Tipo Go |
| PIC S9(n) |
string |
| PIC S9(n) COMP-3 |
string |
| PIC S9(n) COMP o COMP-4 o BINARY |
string |
El programa que realiza la llamada deberá asegurar que el dato enviado corresponde a un valor numérico.
Las variables recibidas deberán ajustarse a la máscara definida en la cláusula PIC, respetando el número de posiciones enteras y decimales y justificando con ceros por la izquierda en caso de ser necesario.
Proceso de conversión
Vamos a partir de un sencillo ejemplo, un programa COBOL que recibe una estructura de datos con distintos tipos de variables.
******************************************************************
IDENTIFICATION DIVISION.
PROGRAM-ID. vars.
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
DATA DIVISION.
FILE SECTION.
WORKING-STORAGE SECTION.
* Declare variables in the WORKING-STORAGE section
LINKAGE SECTION.
* Data to share with COBOL subroutines
01 MY-RECORD.
10 CHAR PIC X(09) VALUE SPACES.
10 COMP2 COMP-2 VALUE ZEROES.
10 COMP1 COMP-1 VALUE ZEROES.
10 COMP5D PIC S9(18) COMP-5 VALUE ZEROES.
10 COMP5L PIC S9(9) COMP-5 VALUE ZEROES.
10 COMP5S PIC S9(4) COMP-5 VALUE ZEROES.
10 COMP5UD PIC 9(18) COMP-5 VALUE ZEROES.
10 COMP5UL PIC 9(9) COMP-5 VALUE ZEROES.
10 COMP5US PIC 9(4) COMP-5 VALUE ZEROES.
10 NDISPLAY PIC S9(3)V9(2) VALUE ZEROES.
10 COMP3 PIC S9(3)V9(2) COMP-3 VALUE ZEROES.
10 COMP4D PIC S9(8)V9(2) COMP VALUE ZEROES.
10 COMP4L PIC S9(3)V9(2) COMP VALUE ZEROES.
10 COMP4S PIC S9(2)V9(2) COMP VALUE ZEROES.
PROCEDURE DIVISION USING BY REFERENCE MY-RECORD.
* code goes here!
DISPLAY "char: " CHAR.
DISPLAY "comp-2: " COMP2.
DISPLAY "comp-1: " COMP1.
DISPLAY "comp5 double: " COMP5D.
DISPLAY "comp5 long: " COMP5L.
DISPLAY "comp5 short: " COMP5S.
DISPLAY "comp5 Udouble: " COMP5UD.
DISPLAY "comp5 Ulong: " COMP5UL.
DISPLAY "comp5 Ushort: " COMP5US.
DISPLAY "display: " NDISPLAY.
DISPLAY "comp-3: " COMP3.
DISPLAY "comp double: " COMP4D.
DISPLAY "comp long: " COMP4L.
DISPLAY "comp short: " COMP4S.
MOVE 0 TO RETURN-CODE.
GOBACK.
A continuación analizaremos dicha estructura (se puede parsear de manera automática) y generaremos dos ficheros:
Un fichero de configuración (vars.yaml) con las características de las variables COBOL presentes en la estructura a convertir (nombre, tipo de variable, longitud, posiciones decimales, signo).
type = 0 -> Variable numérica de tipo DISPLAY
type = 1 -> Variable numérica de tipo COMP-1
type = 2 -> Variable numérica de tipo COMP-2
type = 3 -> Variable numérica de tipo COMP-3
type = 4 -> Variable numérica de tipo COMP-4 o BINARY o COMP
type = 5 -> Variable numérica de tipo COMP-5
type = 9 -> Variable alfanumérica de tipo CHAR
---
copy:
- field: "Char"
type: 9
length: 9
decimal: 0
sign: false
- field: "Comp2"
type: 2
length: 0
decimal: 0
sign: true
- field: "Comp1"
type: 1
length: 0
decimal: 0
sign: true
- field: "Comp5Double"
type: 5
length: 18
decimal: 0
sign: true
- field: "Comp5Long"
type: 5
length: 9
decimal: 0
sign: true
- field: "Comp5Short"
type: 5
length: 4
decimal: 0
sign: true
- field: "Comp5Udouble"
type: 5
length: 18
decimal: 0
sign: false
- field: "Comp5Ulong"
type: 5
length: 9
decimal: 0
sign: false
- field: "Comp5Ushort"
type: 5
length: 4
decimal: 0
sign: false
- field: "NumDisplay"
type: 0
length: 5
decimal: 2
sign: true
- field: "Comp3"
type: 3
length: 5
decimal: 2
sign: true
- field: "CompDouble"
type: 4
length: 10
decimal: 2
sign: true
- field: "CompLong"
type: 4
length: 5
decimal: 2
sign: true
- field: "CompShort"
type: 4
length: 4
decimal: 2
sign: true
Un fichero (request.go) con la representación en Go de la estructura COBOL.
package request
type Request struct {
Char string
Comp2 float64
Comp1 float32
Comp5Double int64
Comp5Long int32
Comp5Short int16
Comp5Udouble uint64
Comp5Ulong uint32
Comp5Ushort uint16
NumDisplay string
Comp3 string
CompDouble string
CompLong string
CompShort string
}
Y por último, un fichero (response.go). Podemos copiar la estructura utilizada anteriormente ya que los parámetros utilizados por el programa son de entrada/salida.
package response
type Response struct {
Char string
Comp2 float64
Comp1 float32
Comp5Double int64
Comp5Long int32
Comp5Short int16
Comp5Udouble uint64
Comp5Ulong uint32
Comp5Ushort uint16
NumDisplay string
Comp3 string
CompDouble string
CompLong string
CompShort string
}
Ya tenemos todo lo necesario para ejecutar nuestro programa COBOL.
Ejecución programa de prueba
A continuación se explica cómo ejecutar el programa de pruebas anterior.
Los ejemplos pueden descargarse directamente del repo de GitHub
La estructura de directorios del ejemplo (d8vars), es la siguiente:
├── cmd
├── cobol
├── conf
├── internal
│ └── cgocobol
│ └── common
│ └── service
├── model
│ └── request
│ └── response
├── test
│ go.mod
│ go.sum
| Dockerfile
/cobol
Contiene los programas COBOL compilados que se vayan a ejecutar (*.dylib o *.so).
Utilice las siguientes opciones de compilación para definir el comportamiento requerido en los campos de tipo binario.
cobc -m vars.cbl -fbinary-byteorder=native -fbinary-size=2-4-8
/conf
Ficheros de configuración descritos anteriormente, utilizados para describir la estructura de la COPY COBOL.
/model
Contiene la definición de las estructuras de datos en Go (request/response).
/internal
En este caso, podemos encontrar una versión simplificada del código necesario para la conversión de datos entre lenguajes y la ejecución de los programas COBOL.
/test
Por último, el directorio test contiene una utilidad para generar datos de prueba aleatorios de acuerdo a los tipos de datos definidos en el programa COBOL.
Para ejecutar el código sólo hace falta ir al directorio /cmd, abrir un terminal y escribir
go run .
Recuerde definir al runtime del lenguaje COBOL, el directorio donde se encuentran los módulos a ejecutar
export COB_LIBRARY_PATH=/User/my_dir/d8vars/cobol
Puede utilizar el programa COBOL de ejemplo loancalc.cbl para realizar pruebas adicionales, simplemente compile el programa y modifique los ficheros de configuración y estructura de datos.
Modifique el fichero app.env para definir el nombre del programa COBOL a ejecutar y el nombre de la COPY COBOL a convertir.
COBOL_PROGRAM="loancalc"
COBOL_CONFIG="loancalc.yaml"
Copie el fichero loancalc.yml a la carpeta conf
---
copy:
- field: "PrincipalAmount"
type: 0
length: 7
decimal: 0
sign: true
- field: "InterestRate"
type: 0
length: 4
decimal: 2
sign: true
- field: "TimeYears"
type: 0
length: 2
decimal: 0
sign: true
- field: "Payment"
type: 0
length: 9
decimal: 2
sign: true
- field: "ErrorMsg"
type: 9
length: 20
decimal: 0
sign: false
Y sustituya las estructuras request.go y response.go por las siguientes:
package request
type Request struct {
PrincipalAmount string
InterestRate string
TimeYears string
}
package response
type Response struct {
Payment string
ErrorMsg string
}